

Battle of data platforms: Data bricks vs Snowflake
Data platforms mentioned in your original request are Databricks and Snowflake. These platforms offer cloud-based solutions for data storage, processing, and analysis, making it easier for organizations to harness the power of their data for insights and decision-making.
Before getting into the details of both the platforms let’s try to check a very basic Big Data Architecture.
The left-hand side of the spectrum deals with a solid Data Ingestion pattern implementation. As we move right it is more about usability by the business which could be mostly Analytical Reports or more intelligently Machine Learning Aided solutions.
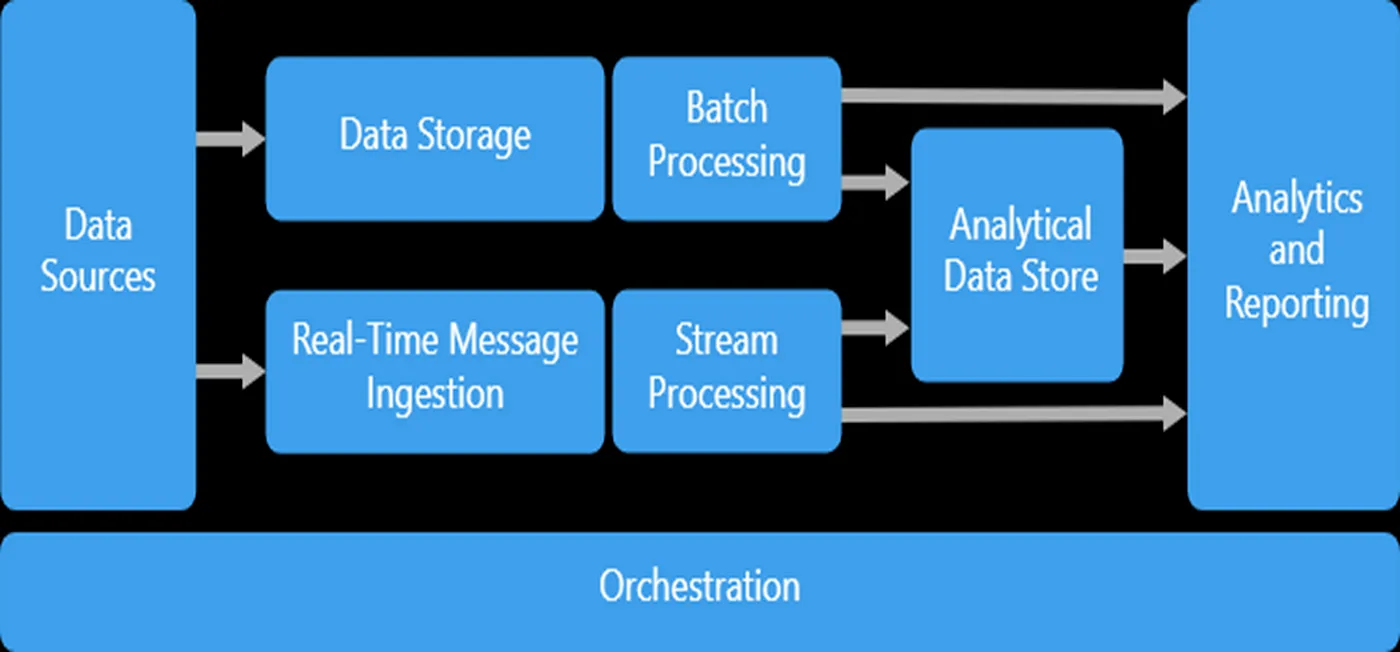
- So the data platforms could be called an integrated analytics platform.
- Only that can capture the Big Data realm from the left-hand side to the right-hand side of the above diagram.
- It’s a win-win situation for Organizations onboarding an Integrated Analytics Platform.
- Their total cost of ownership decreases over a while because now they have to manage and tame just one data platform tool. Databricks started from the left hand of the spectrum as a robust ETL/ELT tool and positioned itself as a good contender for analytical workloads with the release of SQL Analytics.
- Snowflake on the other hand started from the right-hand of the spectrum as a Cloud Data Warehouse with unlimited scale.
- Slowly entered the ETL/ELT space with Snowpipes.
- Catering to Machine Learning needs through the release of Snowpark in 2022.
Below are few of my learnings gathered working on both the platforms:
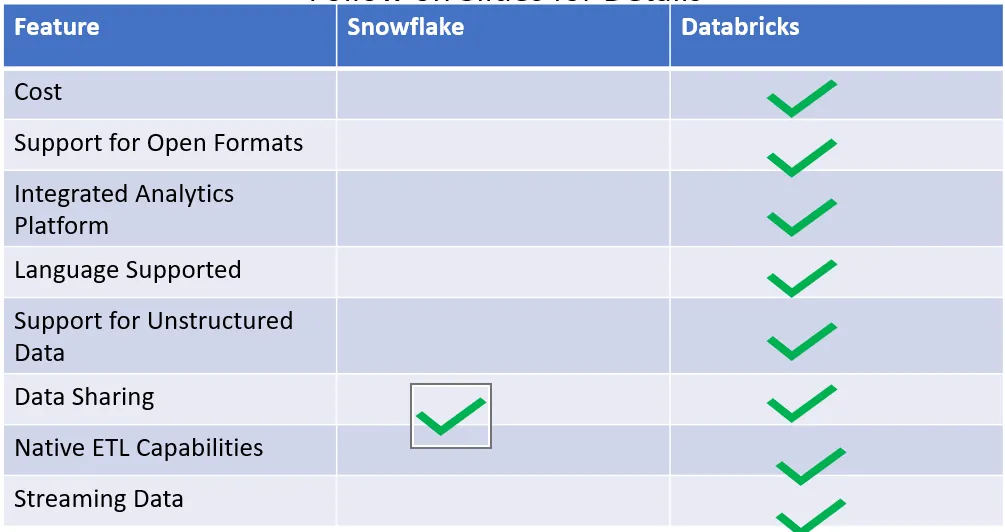
Follow on below for deep dive:data platforms
Cost- This feature is very important in deciding on which data platforms to be invested in:
- Databricks has transparent costing based on reserved VM and time for processing available on Azure Pricing Calculator.
- Snowflake cost for storage flat(23$ per TB)and processing cost based on usage and size of Snowflake Cluster.
Support for Open Formats- This feature prevents Vendor Locking
- Databricks unifies your data ecosystem with open standards and formats.
- Data the stored in Delta Lake, an open-format storage layer. It delivers reliability, security, and performance on your data lake for both streaming and batch operations.
- The stored in a cloud storage account can be read by a compatible reader. This gives you to flexibility leverage other compute data platforms without moving the data
- With Snowflake, data stored in a proprietary format the Snowflake’s own account and is accessible only through Snowflake’s virtual warehouses.
- This results in vendor lock-in because Snowflake runs in its own tenant space. It can be more complex to integrate into a surrounding Cloud Service Providers (CSP) ecosystem.
- Bifurcated security and metadata policies, and the need to copy data between tenant spaces, add to the deployment complexity.
End to End Integrated Analytics Platform- This feature prevents investment in multiple Big Data tools
- Databricks is a completely integrated Analytics platform in itself no need for disparate tools to complement its capabilities.
- Snowflake primarily supports Data Analysts and SQL Developers, while relying on partners to support DS/ML teams with separate tools.
- To capture the full value of data, analytics, and AI with Snowflake, organizations must integrate multiple, disparate tools, resulting in increased complexity, and higher costs.
Languages Supported- This feature support in bringing different persona roles on the Platform
- Databricks allows developers to work in their programming language of choice (Python, SQL, Scala, R).
- Natively leverage the most popular open-source ML libraries and leading frameworks, including TensorFlow and PyTorch.
- Within Snowflake Java and python is supported via User Defined functions in Snow park. No support for R or Scala.
Support for Structured/Unstructured and Semi Structured Data
- Databricks Lakehouse Platform can natively ingest, process, and store. Power all downstream use cases, including unstructured data like images, video, audio, and text.
- Databricks enables optimized access to unstructured data that scales from a single node to massively parallel processing.
- Snowflake was the designed for structured and semi-structured data and has only recently announced limited support for unstructured data types.
- The announced capabilities focus on document management and governance. To analyze unstructured files, Snowflake requires developers to either write, compile. Uploading custom Java Jar files or inefficiently calling external functions like AWS Lambda.
Data Sharing to augment Data platform as a product
- Databricks Delta Sharing is an open protocol for secure data sharing. It simplifies sharing data between organizations, despite differences in data platforms and storage locations.
- Users can directly connect to the shared data through pandas, Tableau, or dozens of other systems that implement the open protocol.
- Snowflake uses proprietary data sharing, which only works between Snowflake accounts, and locks the community of customers, suppliers, and partners into a single vendor platform.
- For recipients who are not Snowflake customers, providers have to manage and pay for “Reader Accounts”, including the compute charges to query shared data.
- Resulting in an unnecessary burden on the providers to manage and pay for reader accounts.
- If customers want to share data with consumers across different clouds or cloud regions, Snowflake’s approach is to create multiple replicas of a database.
- This approach results in access control, data lineage and storage costs issues.
- Also, Snowflake replication for data sharing does not work if the primary database has external tables or if a primary database was created from a share.
Native ETL Capabilities
- Databricks provides an end-to-end data engineering solution with declarative pipeline development, automatic data testing, and deep visibility for monitoring and recovery.
- Auto Loader simplifies data ingestion by incrementally and efficiently processing new data files.
- Delta Live Tables abstracts complexity for managing the ETL lifecycle by automating and maintaining data dependencies, leveraging built-in quality controls with monitoring.
- Providing deep visibility into pipeline operations with automatic recovery.
- Snowflake provides limited native ETL capabilities requiring Snow pipe for data ingestion and COPY INTO command for basic transformations.
- organizations are the forced to the leverage third-party orchestration, data quality, and monitoring tools (i.e. dbt, Azure Data Factory, Informatica, Matillion, etc.) for complex ETL at scale.
Support for Streaming Data
- Data bricks can directly read from the most popular streaming sources.
- Including Kafka, Amazon Kinesis, Azure Event Hubs, APIs, flat files, images, videos, and supports programmatic interfaces that allow you to specify arbitrary data writers.
- Data bricks streaming continuously reads changing data without additional complexity.
- Snowflake has limited support for streaming and takes a data-warehouse-centric approach, loading records into a stage.
- Data in a other common streaming sources must saved to cloud storage before loading into Snowflake.
- Snowflake does not support streaming unstructured data (images/videos/audios).
- Snowflake only supports Kafka as a streaming source and offers a connector which has fault-tolerance limitations.
- While it supports ingestion from streaming sources, Snowflake does not have the ability to process data in a streaming manner once the data has been ingested.
- Parting with my thoughts -Who ever wins in this battle of data platform it is the end users who will be benefitted.

