

Data Bricks Ingest easily load Data for BI
Organizations need to do Business Intelligence(BI) as well as ML both these use cases cater to different set of users and serves close to different use cases.
Data Warehouse — > Data Analysts and Business users get insights from structured Data — >BI.
Data Lakes →Where Data Scientists can explore data and build models from the data.
(Structured/Unstructured/Semi Structured) — >ML.
The above business use case was catered to using two different systems the Data Warehouse and the Data Lake.
BI Challenges with using the above system
Data Warehouses are usually proprietary and closed. Usually they store historical data. Even though Data Warehouse has reliable data it does not support all our Data Science needs.
Data Lake on the other hand built on open standards supports both Data Science and Machine Learning. Even though Data Lake has real time data the data might be messy and unusable at times. SQL support on all the data is also not possible.
Moving data between Data Lake and Data Warehouse also introduces complexities
This lead to the evolution of a new paradigm for BI and ML called the Lakehouse.
Lakehouse enforces data storage in Delta format(read my previous blog to understand Delta https://link.medium.com/C9ZQj1rBi5) and using spark to access them in multiple usage patterns ML to SQL.
BI Lakehouse brings the best of both world
Built on Open Standards supporting SQL+ Data Science+ Machine Learning.
Can capture/has real time and historical data.
Data is reliable and organized.
The evolution traced in BI below:
Until 2010 was year of Data Warehouse. — ->2010 to 2020 was year of Data Lake — →But now 2020 and beyond we are entering into a new era called the Lake House era
Addressing the above problems the Databricks way
BuiltLoading Data into Data Lakehouse is very challenging as we need to deal with hundred different applications, input sources and hundreds of formats and hundreds of API’S to integrate with these systems and ongoing maintenance for all integration systems.
BuiltData Bricks ingest is aimed to ease data In flow process to Data Lakehouse. what are the common scenarios we come across during data ingestion process?
BuiltIngestion from third party data sources. In case of Databricks the partners have built native integrations with Delta Lake. Below are some of the partners:
Data Ingestion Network of Partners
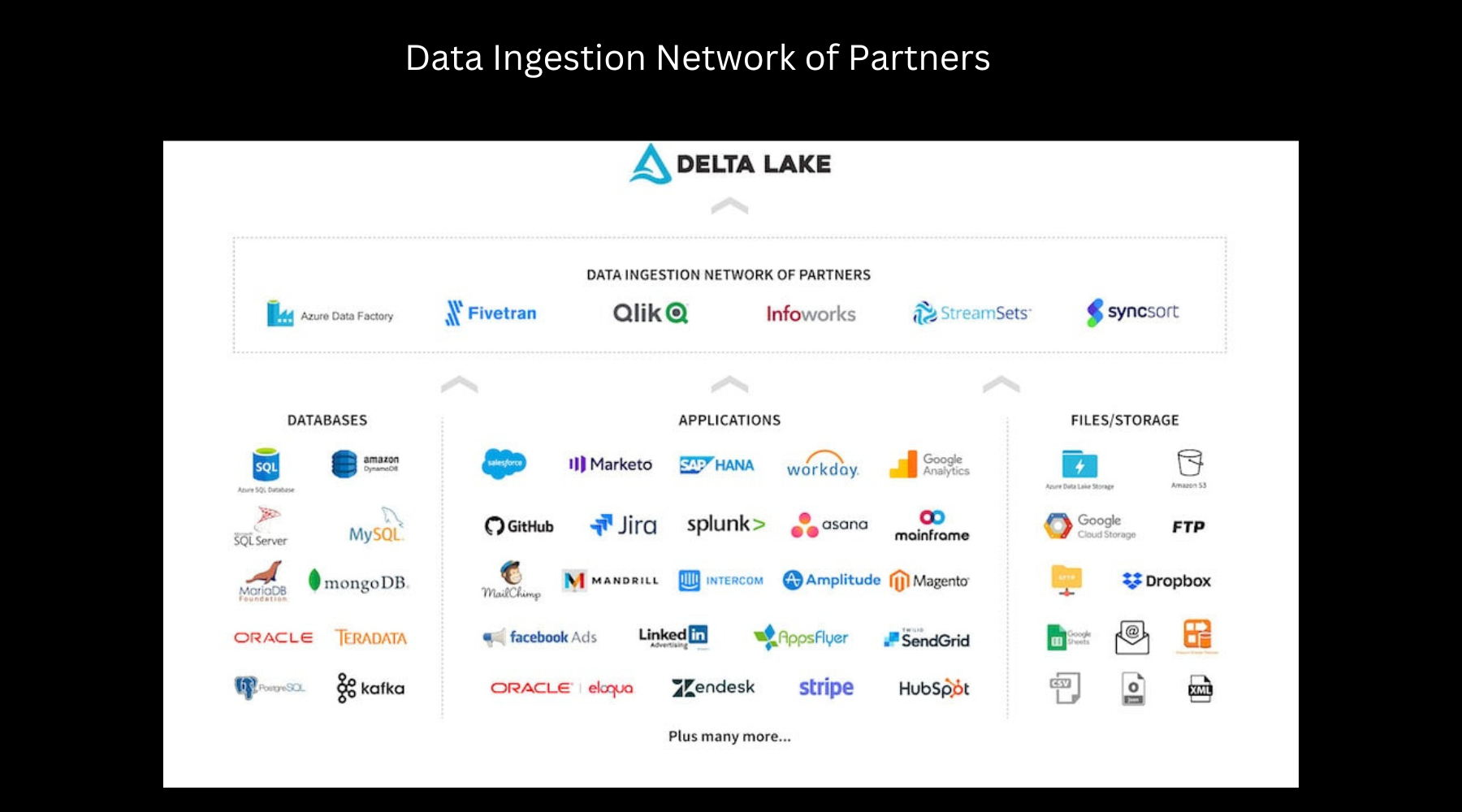
Built in Integrators Databricks partners
Ingestion from cloud
storage- In our Data Lake we have data coming to our ADLS folders at different time of batch. A common pattern is to have three Delta table within Delta Lake boundary in our cloud storage.
Bronze Table- Just collect the data from different sources the most raw form of data.
Silver Table-It is a refined table.
Gold Table- It is a featured/aggregated table ready for consumption.
Once data is in Delta table we can write ETL or write ad-hoc queries we get reliable data out of it:
But when data gets into our cloud as a CSV(batch) we need to process data correctly so for that we need to have custom book keeping to have a notion of which data came in so that in case of failures we can do a manual fix.
For ingesting batch data we usually go for delayed scheduling of ingest jobs(say if we know data load comes in our source system at 04:00 hours we schedule our data pull activity at around 07:00 hours)or via some trigger start the job when we are assured data might have come in our source system.
Similarly in case of Streaming data dump happens frequently so it is very difficult to do manual book keeping. For ingesting streaming data we may have to use cloud notification to start our ingest jobs.
Auto Loader at BI
Comes in Databricks Auto Loader to solve above problems when data lands in the cloud. Most of the problems discussed above are handled out of the box using Databricks Autoloader.
Auto Loader is optimized cloud file source that you can pipe data in by pointing to a directory this is the same directory where input data comes as soon as data comes push the data to delta table. The best part is there is no overhead in managing the data ingests going forward.
Using the AutoLoader
valdf=spark.readStream.format(“cloudFiles”).option(“cloudFile.IncludeExistingFiles”,false). option(“cloudFiles.format”,”json”).load(“/input/path”)
df.writestream.format(“delta”).option(“checkpointLocation”,”/checkpoint/path”).start(“/out/path”)
The above command sets up cloud services behind the scene you we need not worry about anything on behalf of users.
The above case is for streaming data imagine you have a scenario where data comes only once so we may not need our cluster to be running always in such cases to avoid on costs.
We can trigger the same job only once as below
valdf=spark.readStream.format(“cloudFiles”).option(“cloudFile.IncludeExistingFiles”,false) .option(“cloudFiles.format”,”json”).load(“/input/path”)
df.writestream.format(“delta”).trigger(Trigger.once).option(“checkpointLocation”,”
/checkpoint/path”).start(“/out/path”)
The above command starts job processes new files arrived and shuts job and cluster after loading new files.
Using Auto Loader there is no need for book keeping manually. Job starts looks for new files in the source system if arrived copies data to destination and shuts down the job cluster.
Similar functionality could be achieved using SQL API as below for Batch jobs.
COPY INTO tableidentifier FROM{location|(SELECT identifierList FROM location)}FILEFORMAT={CSV|JSON|AVRO|PARQUET|ORC}[FILES=(‘’[,])][Pattern=’’][FORMAT_OPTIONS(‘dataSourceReaderOption’=’value’)][COPY_OPTIONS(‘force’={‘false’,’true’})]
The copy command above is idempotent all the input files loaded are tracked so rerunning the same command produces same results thus preventing duplicate data from loading.
Highlighting the benefits of AutoLoader
No custom book keeping — Incrementally copies new files as they land on the source system and customers don’t need to manage any state information on what files have been copied.
Scalable — Tracks new files arriving by leveraging cloud notification and queue services without having to list all the files in the directory. Scalable to handle million of files in the directory.
Easy to use — Automatic setup of cloud notification and queue service.

