Data lake Table Formats
Apache Iceberg and Apache Hudi? Delta lake?
Data is an Data lake can often be stretched across several files. We can engineer and analyze this data using R, Python, Scala and Java using tools like Spark and Flink.
Being able to define groups of these files as a single dataset, such as a table, makes analyzing them much easier (versus manually grouping files, or analyzing one file at a time).
Questions below should help you future-proof your Data lake and inject it with the cutting-edge features newer table formats provide
- The most robust version of the features I need in Which format?
- Which format enables me to take advantage of most of its features using SQL so it’s accessible to my data consumers?
- The momentum with engine support and community support in which format?
- Which format will give me access to the most robust version-control tools?
First-Generation Table Format- HIVE in Data lake
In Hive (original table format), a table is defined as all the files in one or more particular directories.
Comparison Parameters
1.ACID Transactions
Apache Iceberg approach is to define the table through three categories of metadata.
These categories are
- “metadata files” that define the table. “manifest lists” that define a snapshot of the table.
- “manifests” that define groups of data files that may be part of one or more snapshots. Iceberg provides snapshot isolation and ACID support.
- When an query is an run, Iceberg will use the latest snapshot unless otherwise stated.
- Writes to any given table create a new snapshot, which does not affect concurrent queries. Concurrent writes are an handled through optimistic concurrency.
- Apache Hudi approach is to group all transactions into different types of actions that occur along a timeline.
- Hudi uses directory-based approach with files that are timestamped and log files that track changes to the records in that data file.
Delta Lake approach is to track metadata in two types of files
- Delta Logs sequentially track changes to the table.
- Checkpoints summarize all changes to the table up to that point minus transactions that cancel each other out.It also supports ACID transactions.
2. Partition Evolution
Partition Evolution Partitions are an important concept when you are organizing the data to be queried effectively,Often, the partitioning scheme of a table will need to change over time. It allows us to update the partition scheme of a table without having to rewrite all the previous data.
Apache Iceberg is currently the only table format with partition evolution support.
It’s an tracked based on the partition column and the transform on the column (like transforming a timestamp into a day or year).Delta Lake and Apache Hudi currently do not support it.
3.Schema Evolution
Schema Evolution as data evolves over time, so does table schema.columns may need to be renamed, types changed, columns added, and so forth. In all the three formats We can Add a new column, Drop column, Rename a column, Update a column, Reorder column.
4.Time Travel
Time Travel allows us to query a table at its previous states In general, all formats enable time travel through “snapshots.” Each snapshot contains the files associated with it.Periodically, you’ll want to clean up older, unneeded snapshots to prevent unnecessary storage costs.
Each table format has different tools for maintaining snapshots, and once a snapshot is removed you can no longer time-travel to that snapshot.
5.File Format Support
File Format Support Parquet’s binary columnar file format is the prime choice for storing data for analytics. However, there are situations where you may want your table format to use other file formats like AVRO or ORC.Data files of Delta table could not be AVRO or ORC while Data files of Apache Hudi could not be AVRO.
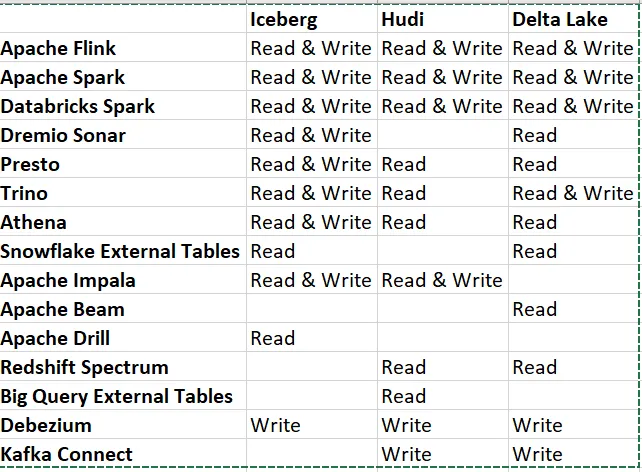
6.Tool Compatibility
Tool Compatibility a table format wouldn’t be useful if the tools data professionals used didn’t work with it.It’s important not only to be able to read data, but also to be able to write data so that data engineers and consumers can use their preferred tools.