Ope-rationalization of Machine Learning Models Part 2
Part 1 covers a very special and unique kind of deplhttps: //logicalmindsit.com/wp-admin/post.php?post=14110&action=editoyment mechanism using SQL Server Machine Learning Services
Model Deployment & Machine Learning using the Azure Data Factory
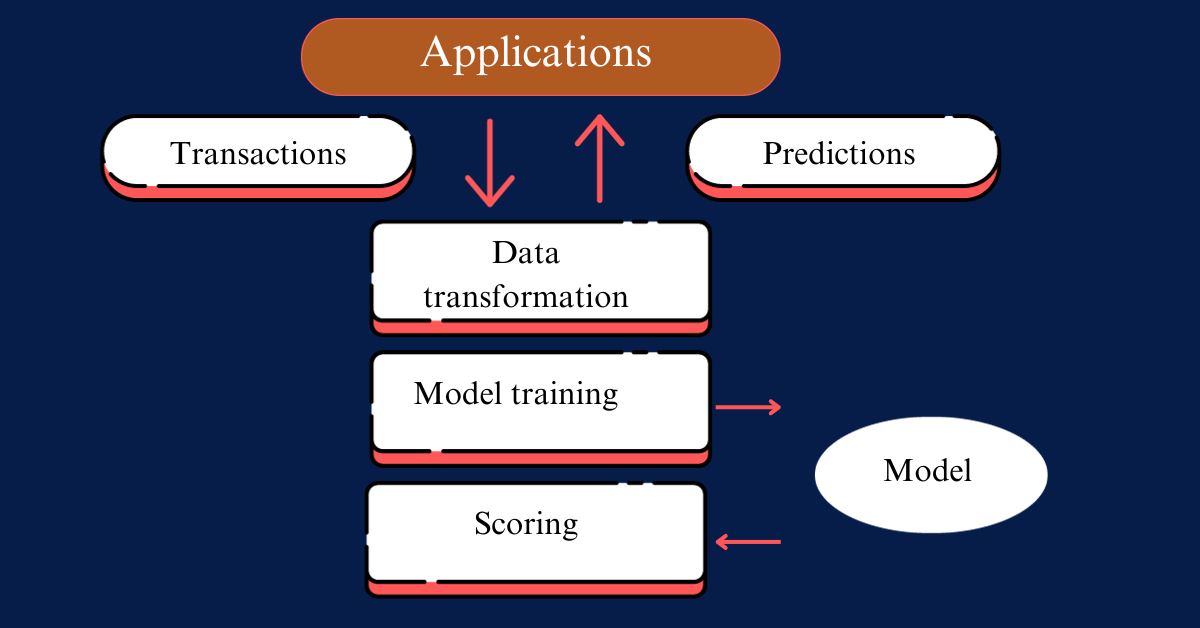
Any Machine Learning project once developed caters broadly to two types of execution patterns.
- In Batch Processing we can program our Models to run at predefine timelines.
- In Real- time Process we can schedule our Models to run the very moment an event has occurred.
Below we talk about how we can use Azure capabilities to ope-rationalize our Machine Learning projects.
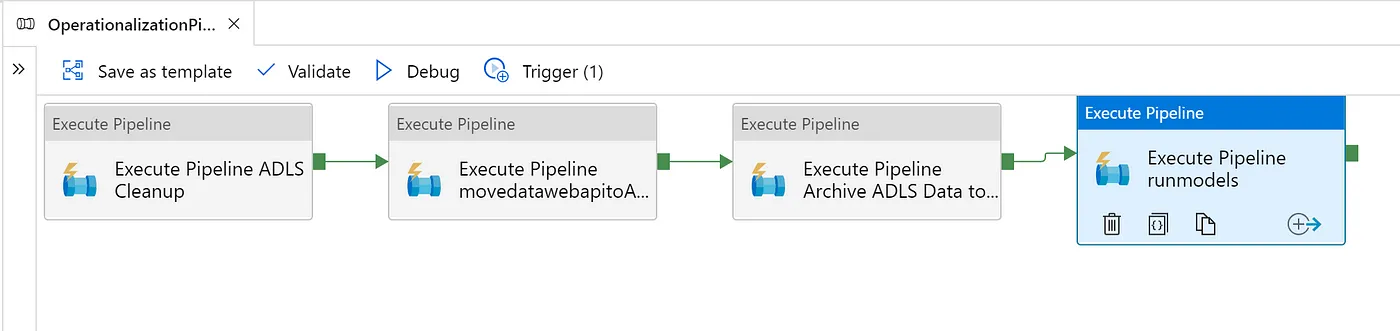
Batch Processing or Event Based Real Time Processing using Azure Data Factory Machine Learning
- Consider a Use case where we know that we need to run our models say every week/month/every six months or yearly after ingesting some set of data from disparate sources for which we have connectivity to Azure Cloud via the Azure Data Factory. A list of incoming connectors can found out at the link https://docs.microsoft.com/en-us/azure/data-factory/connector-overview
- Now for the above use case we know that the data would have been changed over the period defined above and that is why we need to run our complete data pipeline once again before running our model training on the same to get inferences.
- All the above steps in orchestrated in one Azure Data factory pipeline ingesting data from disparate resources, performing data mapping/data wrangling on it ( you can use Azure Data flow/ or Azure Data bricks) for this, and then finally feeding the data to our models in Azure Databricks notebooks. The best part is it can be scheduled as well and you are done.
Sample Steps
- Develop an Azure Data factory with multiple copy activities to ingest data from disparate sources.
- The data ingested from the sources stored in our Azure Cloud Data Lake bronze stage/raw data stage.
- Run Azure Data Flow/Azure Data bricks notebooks to perform Data Wrangling and Data Mapping Activities.
- Save the processed files above in Azure Cloud Data lake silver stage/aggregated data stage.
- Call your Azure Data bricks in the notebook which uses the data from the above- aggregated stage to do data science modelling assuming this has been developed in Notebook environment of Azure Databricks. make sure you do not hard code your file names etc.in the Databricks notebooks rather try making in generic parameterized values which can be changed as per the schedule on which your Data factory is running.
- Schedule it for the designated periods using the Azure Data factory triggers.
Example use case of Machine Learning
- Consider you are developing a system for modeling a Covid pandemic use case and taking data from the government website https://api.covid19india.org/ which has web API’s catering to your use cases returning a JSON/CSV which could, in turn, be used for your modeling and we know the data might change every day so we could schedule it to run every day.
- We need to do some housekeeping as well because we know that every time my model picks up from a specified location so we need to make sure the moment the new data lands in the location we need to archive the old data so that it does interfere with the modeling of new data.
- Also once we have completed the modeling we can store the output in Azure SQL Server so that end results can be consumed within Power BI.
Steps defined below
- Archive Data from my input folder to a different location.
- Copy data from web API’s to ADLS(raw stage).
- Run the Python modeling code in your Azure Data Bricks notebook.
- Write the output files generated from the model to the Azure SQL Server database.
- Trigger it for a daily run