

Some of Azure Databricks Best Practices
Starting with Azure Databricks reference Architecture Diagram.
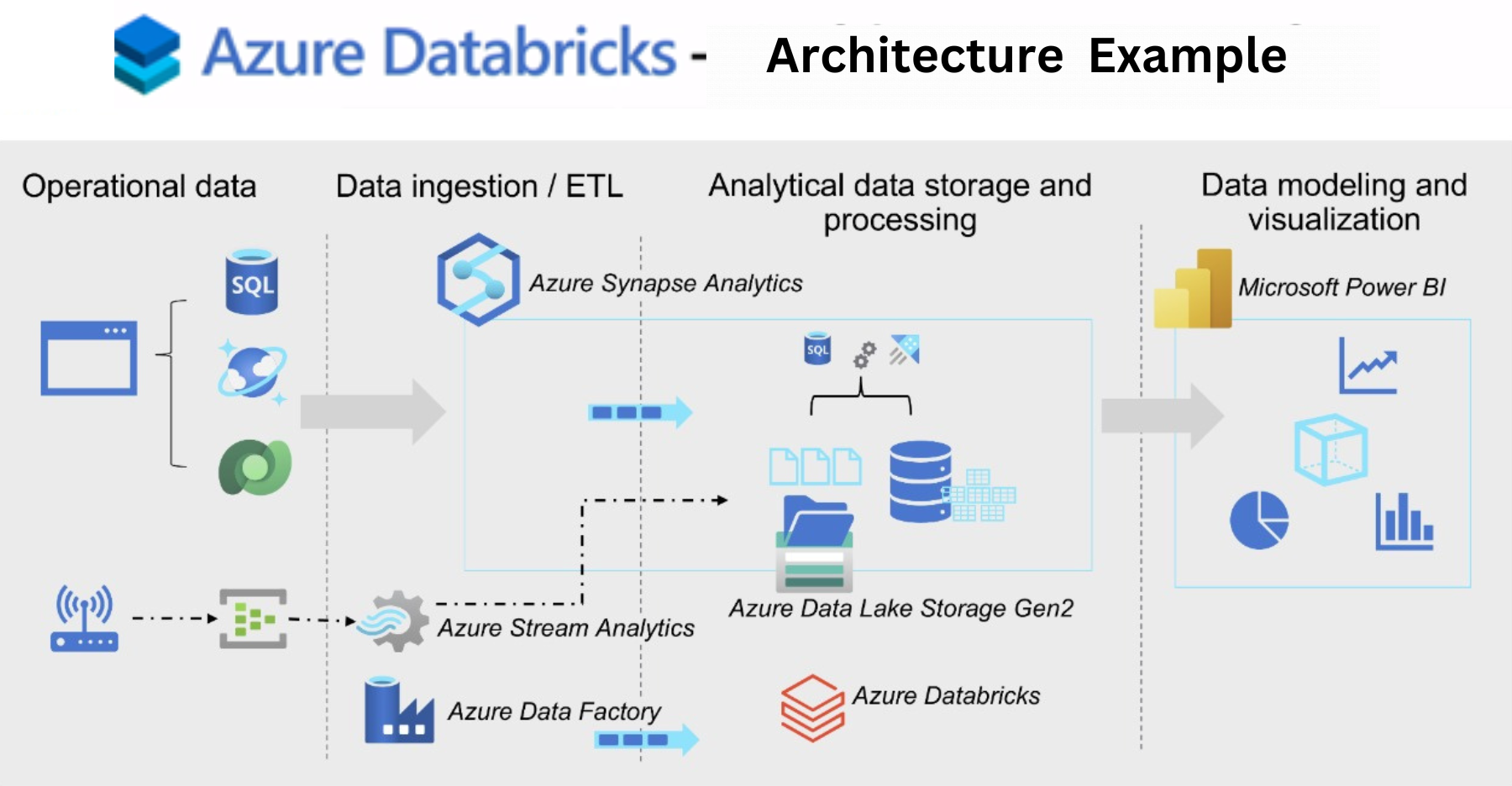
Infrastructure Management Best Practices
Azure Databricks could be provisioned under a top level Tenant Id- Organization identifier followed by Subscription which could be say Prod Non Prod environment subscription on a broader level or say could be Line of Business /Account level demarcation followed by Resource Group drilling down to a specific Project Level Scope.
- Its creates its own managed resource group ,we may not have access to the storage account created within the Azure Data Bricks managed resource group.
- Assign workspaces based on related group of people working collaboratively.
- Streamline your access control matrix within your workspace and all your resources that the workspace interacts with.
- The above type of division scheme is also known as the Business Unit Subscription design pattern and it aligns well with Databricks charge back model (fig below).
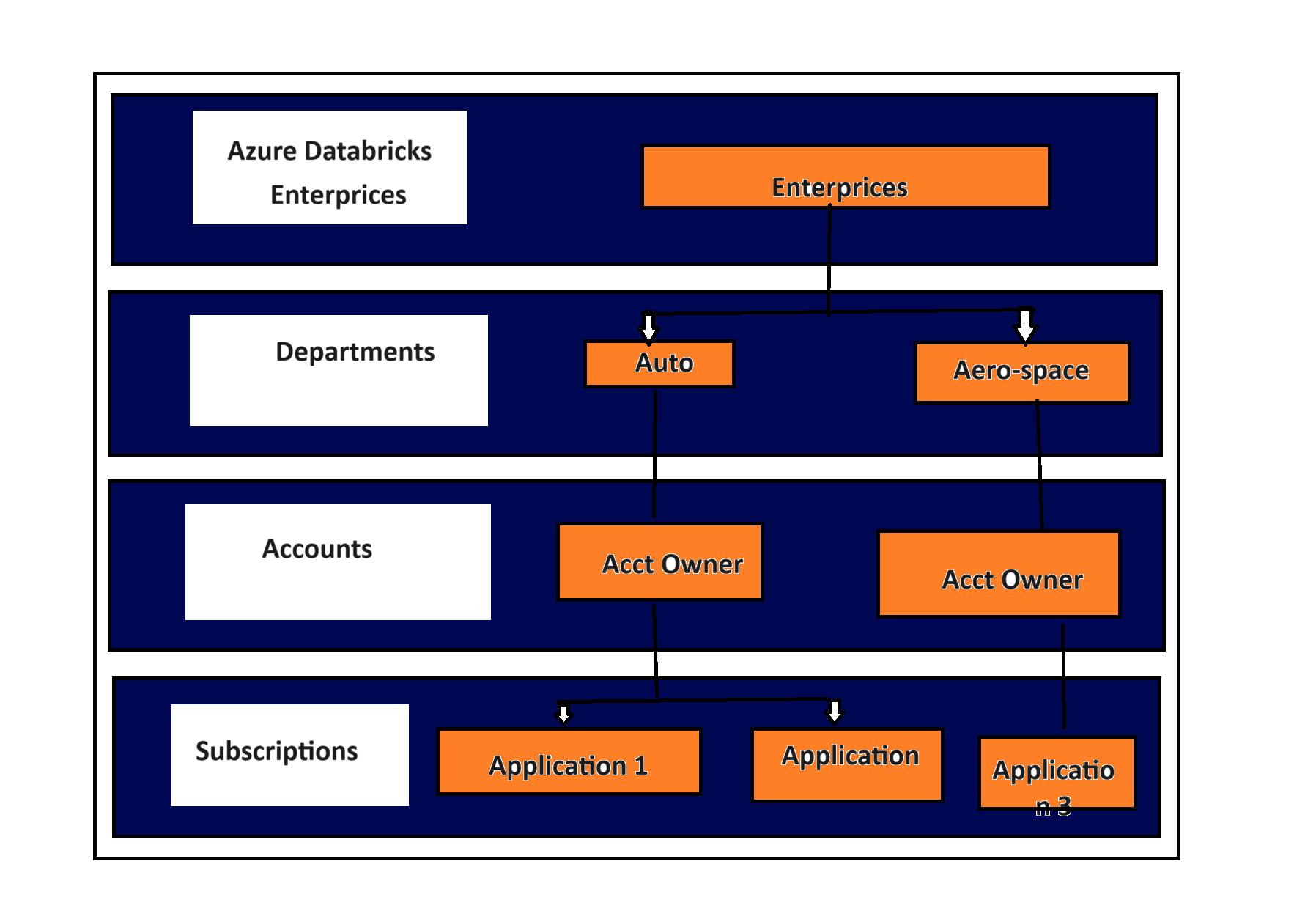
Workspace and Subscriptions Limits
Customers partition workspaces based on teams or departments and Azure Databricks is very important to partition keeping Azure Subscription and ADB workspace limit in mind.
Networking Concepts
V- Net is the virtual boundary associated with your Azure resources so it is advisable to select the largest V-Net CIDR for accurate capacity planning(this feature only applies in case you bring your own V-Net feature.
- Each cluster node requires 1 public and 2 private IP’s . These IPs are logically grouped into 2 sebnets named “public” and “private”.
- For a desired Cluster size of X : number of Public IPs is X and number of private IPs is 4X.
- So indirectly the size of public and private sub nets determine total number of Virtual Machine’s available for clusters.
- The allowed values for the enclosing VNET CIDR are from /16 through /24
Storage and Secure access best practices Azure Databricks
- Never ever store any production data in default DBFS folders as life cycle of default DBFS is tied to the Workspace. Deleting the workspace will delete the DBFS and your production data will be gone for ever.
- Customers cannot restrict access to this default folder and its contents.
- The above recommendations does not apply to ADLS or Blob storage explicitly mounted as DBFS by the end user.
Always store secrets in Key Vault: Use Azure Key Vaults to store your secrets.
https: //#secrets/create Scope
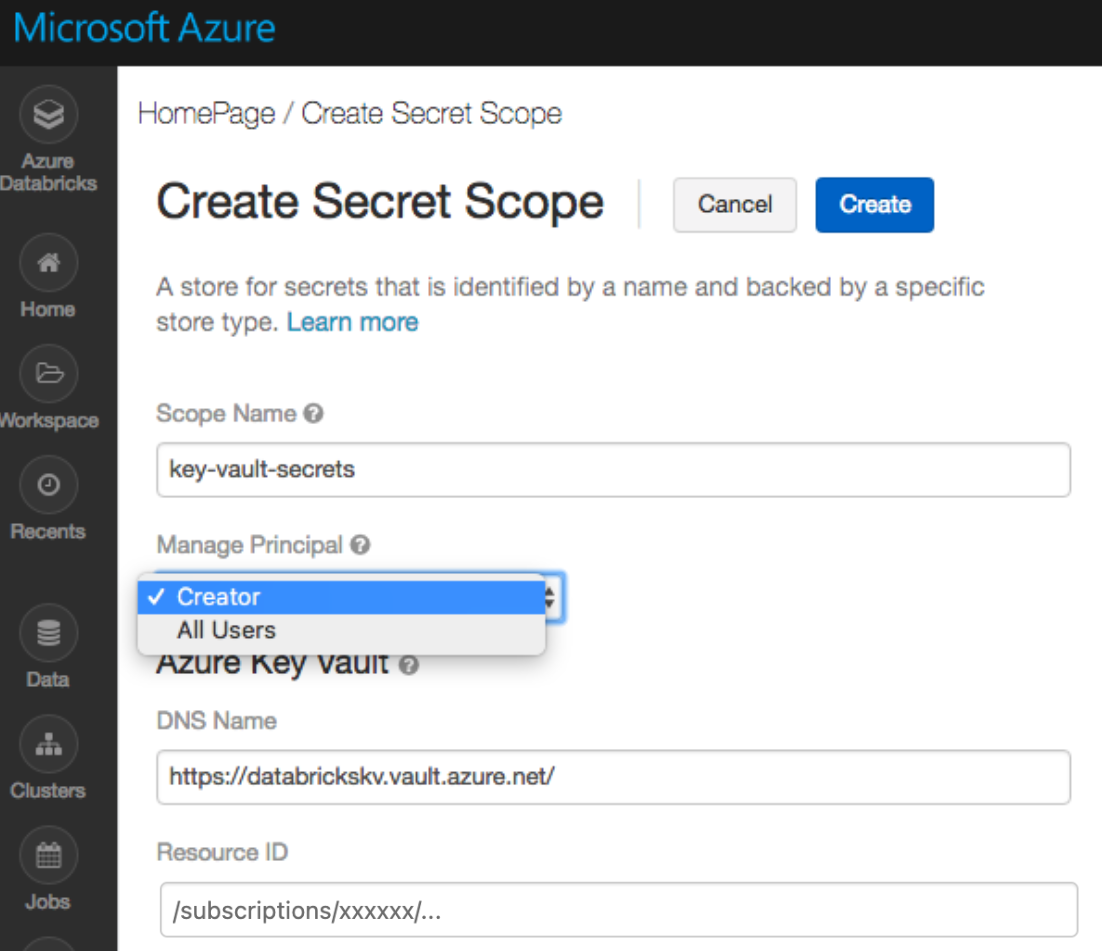
Configuring secure access of ADLS Gen2 applicable to whole group of people across any cluster
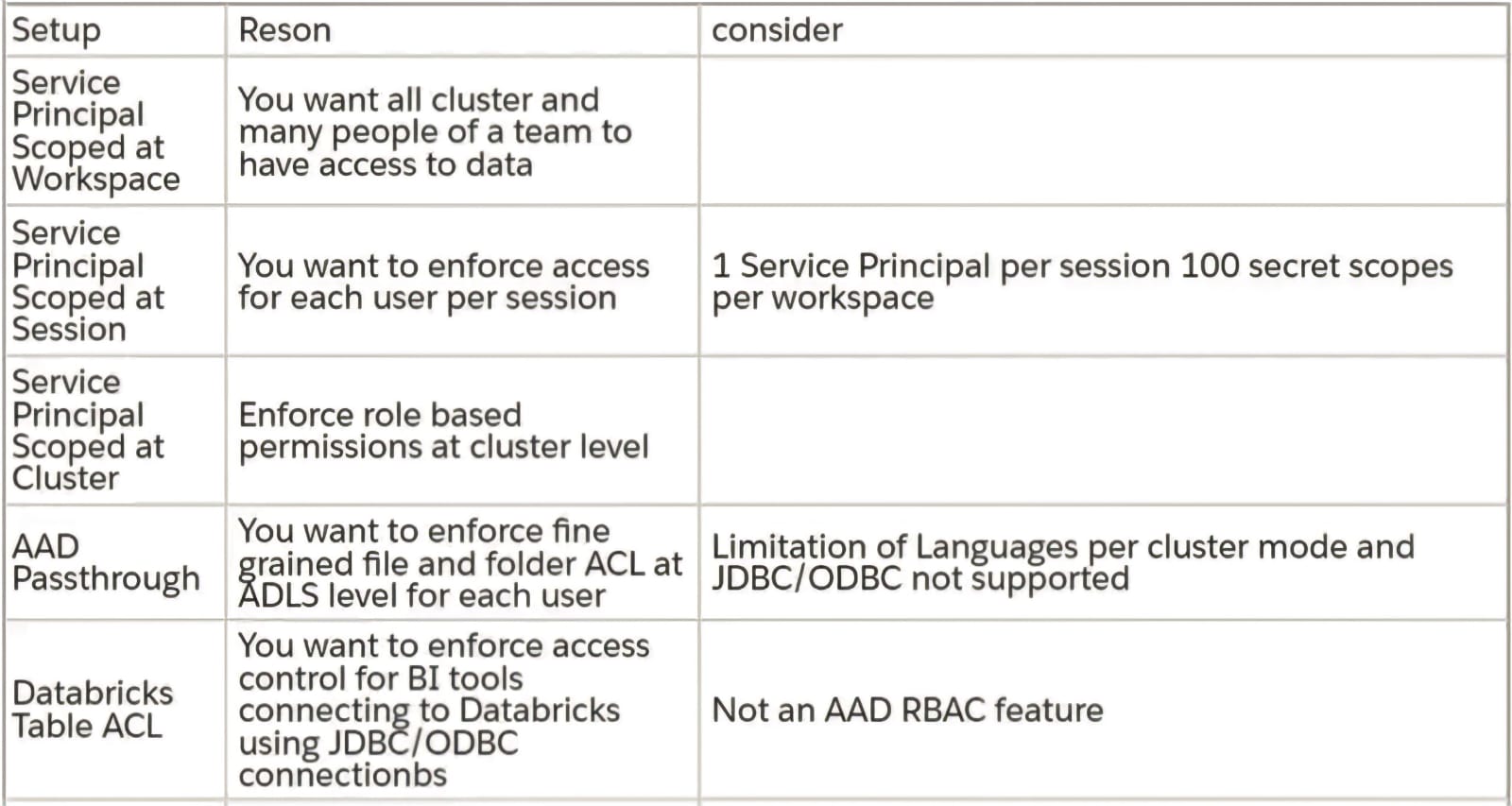
- Service Principal Authentication-If you want to provide a group of users access to particular folder and its contents scope the Service Principal Authentication to:
- Workspace-mount a folder for all clusters to access.
- Cluster-Cluster configuration setting.
- Session-configure Spark conf session with SP
- AAD Passthrough Authentication-In case you wish to enforce fine grained ADLS file and Folder level ACLs for each user individually.
- Databricks Table ACLS- For BI scenarios you can set access controls on Tables and Views.
Cluster Configurations best practices of Azure Databricks
1)Design choices faced by developers.
a)Analytics vs Job Clusters


b)Does my streaming cluster need to be up 24/7- You can execute a streaming workload as a Job cluster if latency is close to an hour.
- Also if the latency requirements are once in a day consider Trigger once mode.
c)Cluster modes to use
d)Performance- Picking the right Virtual Machine General Purpose Compute-Machine Learning Storage Optimized-Streaming and Extract Transform Load jobs Compute Optimized-Interactive Development workloads GPU- Deep Learning workloads.
Exceptions
- Machine Learning could require huge Memory Cache when more computations are involved in that case us.
- Memory 0ptimized RAM but in case our data set is huge go for Storage Optimized RAM.
- In case of Streaming jobs if we want streaming processing to be faster than the input rate go for Compute Optimized Virtual Machines.
- Getting the exact size is workload dependent and only iterative methods work.
- CPU Bound-Add more cores by adding more nodes to the cluster Network Bound-Use fewer and bigger SSD backed machines to reduce network size and improve remote reads.
- Disk I/O bound-If jobs are spilling to disks use Virtual Machines with more memory.
Databricks Pool Considerations
Consider using Pools in case you want to shorten the cluster start time by 7X gives best results for short duration Jobs which needs fast trigger and finish times and it helps speed up time in between job stages.

