

Snowflake and Databricks Complementing the Modern Data Architecture
Databricks and Snowflake both the platforms are marketing themselves as complete end to end AI/ML platform but many organizations are using both the platforms complementing each other to get the best of both worlds together to power an integrated data processing platform.
- How to achieve the use case above? “Spark connector” brings Snowflake into the Apache Spark ecosystem, enabling Spark to read data from and write data to Snowflake.
- The connector provides the Spark ecosystem with access to Snowflake as a fully-managed and governed repository for all data types including JSON, Avro, CSV, XML, machine-born data.
- So why exactly would someone need a Spark Connector for Snowflake? ( Try the new feature of Snowflake Snowpark in preview which removes the usage of a Spark connector)
Databricks Complex ETL
- Complex ETL is the flavor of Databricks- Using Spark you can easily build complex, functionally rich and highly scalable data ingestion pipelines for Snowflake and the data produced by these complex ETL pipelines can easily be stored in Snowflake for broad, self-service access across the organization using standard SQL tools.
- Spark queries benefit from Snowflake’s automatic query pushdown optimization, which improves performance by pushing some of the more resource-intensive processing in Snowflake instead of Spark. By default, Snowflake query pushdown is enabled in Databricks.
- Let’s try understanding the basic Flow of Query between Spark and Snowflake that helps us deep dive into the process of pushdown.
- The Spark driver sends the SQL query to Snowflake using a Snowflake JDBC connection
- Snowflake uses a virtual warehouse to process the query and copies the query result into AWS S3/Azure Blob.
- The connector retrieves the data from S3/Blob and populates it into DataFrames in Spark.
So why Pushdown?
- Spark and Snowflake both are capable of processing all or parts of a particular data task flow. So for the best performance in big data scenario we typically want to avoid reading lots of data or transferring large intermediate results between the interconnected systems. So most of the processing should happens close to where the data is stored to leverage any capabilities of the participating stores to dynamically eliminate data that is not needed.
- Spark supports a good set of functionality for relational data processing and connecting with a variety of data sources. Snowflake can achieve much better query performance via efficient pruning of data enabled through micro-partition metadata tracking and clustering optimizations.
- This metadata allows Snowflake to scan data more efficiently when given query predicates by using aggregate information on micro-partitions, such as min and max values and the data that is determined not to contain relevant values skipped entirely. Metadata such as cardinality of column values allows Snowflake to better optimize for operations such as join ordering.
- Operations such as filter, projection, join, and aggregation on data have the potential to significantly reduce the result set of a given query, the data pruning used by Snowflake could be leveraged. This also has the benefit of reducing data that has to be transferred to Spark via Snowflake staging and the network, which in turn improves response times.
- The cake is Snowflake connector integrates deeply with the query plan generation process in Spark enabling more push down. e.g in the query below
Query Plan Generation within Spark
dfZipCodes.createOrReplaceTempView(“temp_zip_codes”) val dfSQLCities = spark.sql(“SELECT city from temp_zip_codes WHERE zip_code < 98000”)
- DataFrames are executed lazily means Spark evaluate and optimize relational operators applied to a DataFrame and only execute the DataFrame when an action is invoked. Spark delays planning and executing the code until an action such as collect(),show() or count () occurs.
- When an action required, Spark’s optimizer, Catalyst, first produces an optimized logical plan. The process then moves to the physical planning stage. This is where Spark determines whether to push down a query to Snowflake, as shown in the following diagram:
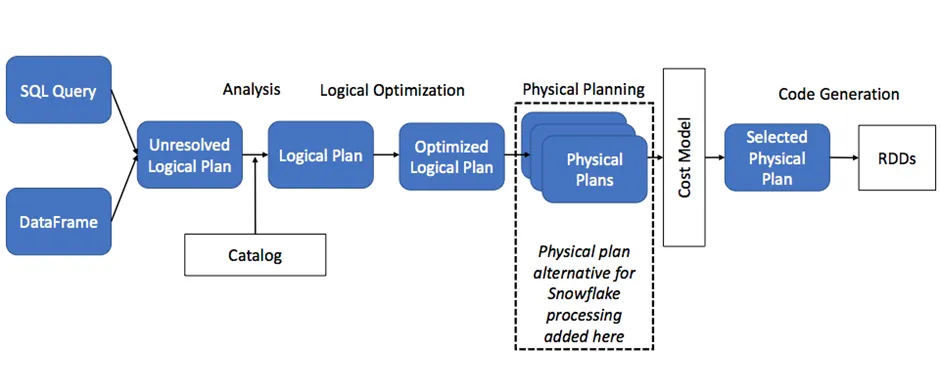
- As we see in the diagram above Spark Catalyst inserts a Snowflake plan as one possible physical plan for Spark to choose based on cost.
- In the above operation Snowflake worker nodes perform all the heavy processing for the data egress, and the slave nodes in the Spark cluster perform the data ingress.
- This allows you to size your Snowflake virtual warehouse and Spark clusters to balance compute capacity and IO bandwidth that gives you virtually unlimited capacity for transferring data back and forth between Spark and Snowflake.
Let’s try to understand the pushdown in New and Old Version of Spark Connector for the query example below
val dfZips =spark.read.format(“net.snowflake.spark.snowflake”).option(“dbtable”,”zip_codes”).load()
val dfMayors = spark.read.format(“net.snowflake.spark.snowflake”).option(“dbtable”,”city_mayors”).load()
val dfResult = dfZips.filter(“zip_code > 98000”).join(dfMayors.select($”first”,$”last”,$”city”,$”city_id”), dfZip(“city_id”) === dfMayors(“city_id”), “inner”)
Every DataFrame is represented as a logical plan tree with nodes representing data sources and operators and the above resultant DataFrame is represented in the tree structure below by Spark
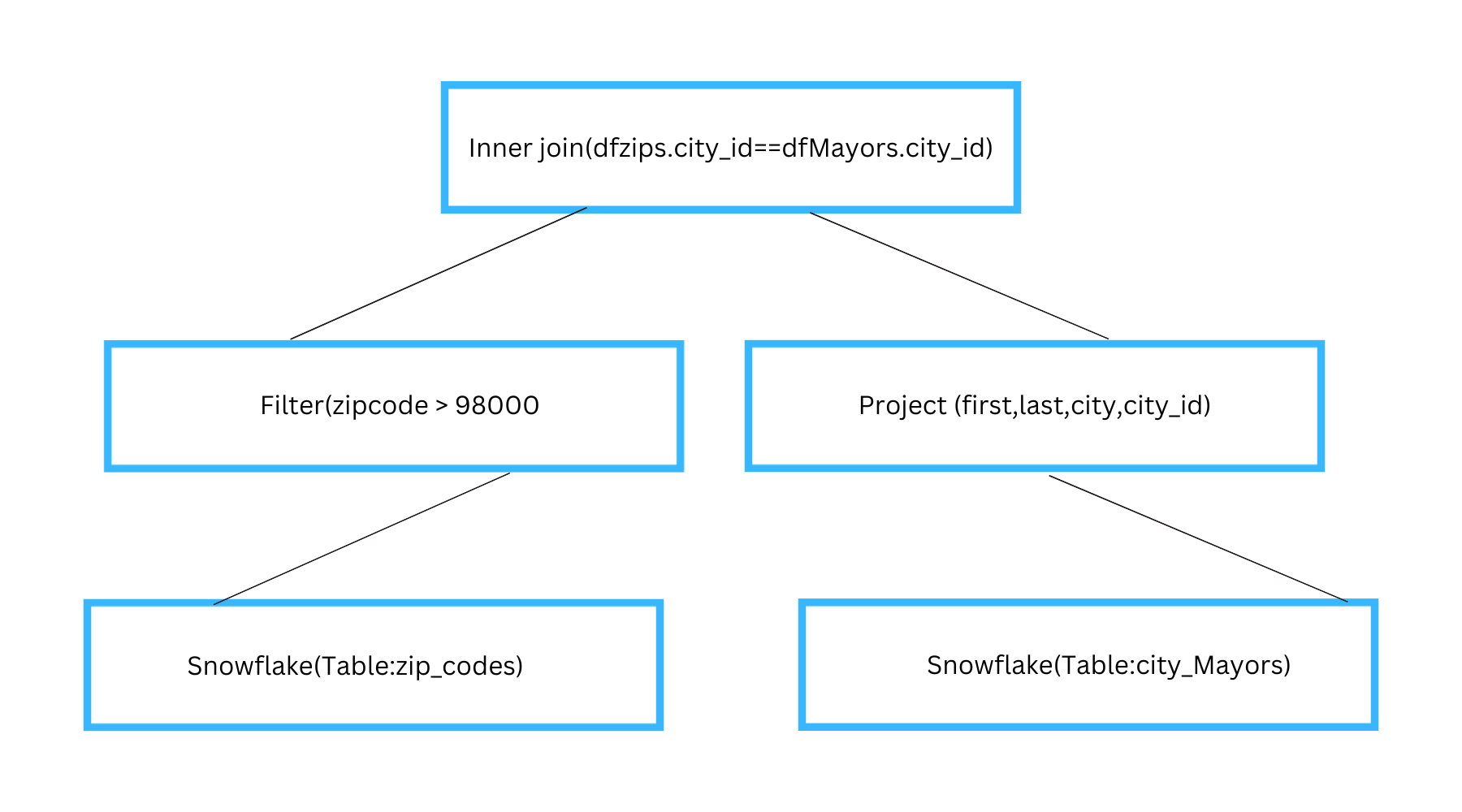
Spark Connector Older Version approach — Simple projection and filter operations (e.g. Select(.) and .Filter(.) in Scala) would be translated and pushed to Snowflake, instead of being processed in Spark however, other operations, such as joins, aggregations, and even scalar SQL functions, could only be performed in Spark.
So in the query example above Spark performs the join on multiple tables forming the final DataFrame
Spark Connector Newer Version approach
- With Snowflake as the data source for Spark, v2.1 of the connector can push large and complex Spark logical plans (in their entirety or in parts) processed in Snowflake enabling Snowflake to do more of the work leveraging its performance efficiencies.
- This approach combines the powerful query-processing of Snowflake with the computational capabilities of Apache Spark and its ecosystem.
- So in the query example above Spark connector tries to verify that multiple tables forming the final DataFrame are joinable relations within Snowflake to be able to recognize that the join can be performed completely in Snowflake.
- The same process above can also applied to SORT, GROUP BY, and LIMIT operations in the newer version
Fault Tolerance
- When pushdown fails because sometimes one-to-one translation of Spark SQL operators to Snowflake expressions is not possible the connector falls back to a less-optimized execution plan and these unsupported operations are instead performed in Spark.
Machine Learning Databricks
- Spark provides a rich ecosystem for machine learning and predictive analytics functionality via MLlib. With the integration, Snowflake provides you with an elastic, scalable repository for all the data underlying your algorithm training and testing.
- The normal process of ML is to use Snowflake for some basic data manipulation, train a machine learning model in Databricks, and write the results back to Snowflake.
Sample code to connect to Snowflake from Databricks
# Use secrets DBUtil to get Snowflake credentials. user = dbutils.secrets.get(“data-warehouse”, “”) password = dbutils.secrets.get(“data-warehouse”, “”)
# snowflake connection options options = { “sfUrl”: “”, “sfUser”: user, “sfPassword”: password, “sfDatabase”: “”, “sfSchema”: “”, “sfWarehouse”: “” }
Sample code to write data to Snowflake from Databricks
# Generate a simple dataset containing five values and write the dataset to Snowflake. spark.range(5).write \ .format(“snowflake”) \ .options(**options) \ .option(“dbtable”, “”) \ .save()
Sample code to read data from Snowflake to Databricks
# Read the data written by the previous cell back. df = spark.read \ .format(“snowflake”) \ .options(**options) \ .option(“dbtable”, “”) \ .load() display(df) df = spark.read \ .format(“snowflake”) \ .options(**options) \ .option(“query”, “select 1 as my_num union all select 2 as my_num”) \ .load() df.show()
Before giving a full stop to the topic one important aspect is the pre requisites
- Databricks account having the runtime version 4.2 and above.
- Snowflake account with details (url, login name and password, default database and schema, default virtual warehouse).
- The role used in the connection needs to Usage and Create Stage privileges on the schema that contains table to read from or write to using Databricks.
Some very important pointers to consider while using Databricks and Snowflake together
- We must explicitly specify the mapping between DataFrame and Snowflake columns using the column map parameter.
- Integer and Decimal are semantically equivalent in Snowflake so when you write data to and read data from Snowflake integer data converted to decimal when writing to Snowflake.
- Snowflake uses uppercase fields by default so the table schema converted to uppercase.
Conclusion
Fully pushing query processing to Snowflake provides the most consistent and overall best performance, with Snowflake on average doing better than even native Spark-with-Parquet.

