

Operationalization of Machine Learning Models Part 1
Model Deployment using the new feature of SQL Server- Machine Learning Service
This kind of machine learning deployment is not widely used /widely known by audience as it caters to only some specific use cases which we discuss below.
- Consider a Use Case where we know that the input data for models will come from Microsoft SQL Database tables.
- Our data already in relational form clean, processed and ready to use for say visualization) ideally such cases happen.
- when we already had a visualization process in place but now your business wants to derive insights from this structured data in terms of predictive algorithms etc.which is not possible via published reports.
- Also as a work around in case you want to use the above method of deployment.
- Not allowed to docker based deployment on Kubernetes due to infrastructure constraints.
- The pre processing of the unstructured/schema less Big data and derive a relational data out of processing so that is ready to saved in your SQL Server Database table.
- Microsoft SQL Server team came up with a mission to bring Machine Learning capabilities within SQL Server versions 2016.
- And above using which you can run python and R scripts containing.
- Machine learning code with relational data the best part in scripts executed in database without moving data outside.
SQL Server or over the network. So rather than your data going to model your model comes to your data
- You can use open-source packages and frameworks, and the Microsoft Python and R packages.
- For Predictive analytics and machine learning Most common open source Python and R packages in pre-installed the Machine Learning Services.
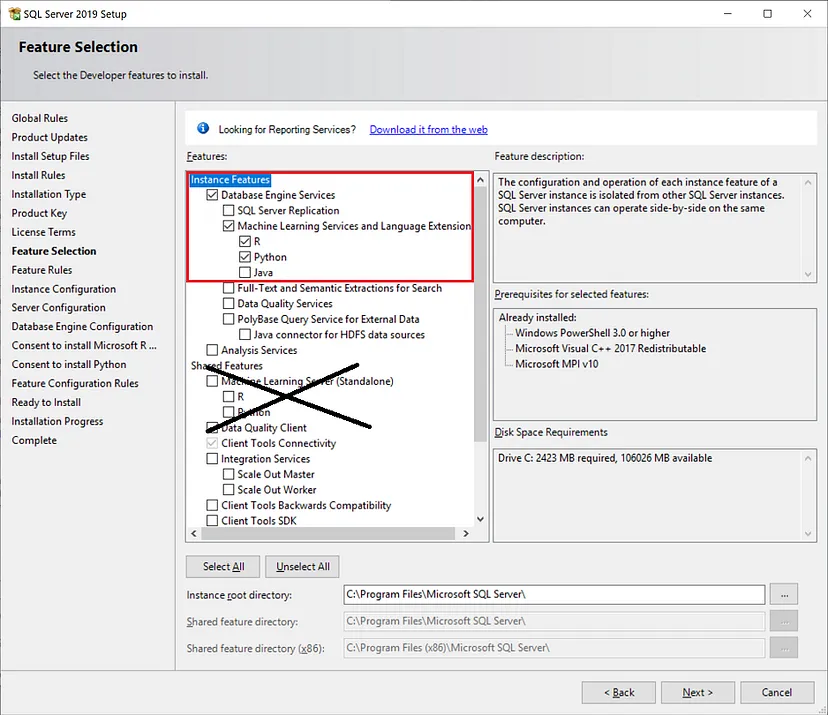
- Getting the Machine Learning feature in your SQL Server is easy it is just a click option as shown below during SQL Server 2016 and above installation.
- The machine learning deployment not a widely used/widely known by audience as caters to only some specific use cases which we discuss below.
- As a work around in case you want to use the above method of using deployment you need to do all the pre processing of the unstructured/schema less Big data.
- And derive a relational data out of your processing so that it is ready to saved to your SQL Server Database table.
- Microsoft SQL Server team came up with a mission to bring Machine Learning capabilities within SQL Server versions 2016.
- And above using which you can run python and r scripts containingMachine learning code.
- with relational data and the best part is scripts are executed in-database without moving data outside SQL Server or over the network.
- So rather than your data going to model your model comes to your data. You can use open-source packages and frameworks, and the Microsoft Python and R packages.
- For predictive analytics and machine learning Most common open-source Python and R packages are pre-installed in Machine Learning Services.
- Getting the Machine Learning feature in your SQL Server is easy it is just a click option as shown below during SQL Server 2016 and above installation..
Time to enable your instance to run R/Python scripts in SQL Server. EXEC sp. configure ‘external scripts enabled’, 1; RECONFIGURE WITH OVERRIDE
Don’t forget to restart your SQL Server Instance after the configuration!-Machine learning
Using SQL Server Machine Learning Services you can execute Python and R scripts in-database.
- You can use it to prepare and clean data, do feature engineering, and train, evaluate, and deploy machine learning models within a database.
- The feature runs your scripts where the data resides and eliminates transfer of the data across the network to another server.
- The magic lies here “You can execute Python and R scripts on a SQL Server instance with the stored procedure sp.execute_external script
- Below table provides the support for external scripts within different versions of SQL Server. Reference to check if your model could be open rationalized using SQL Server capabilities for Machine Learning.

Sample Steps to be followed for Model deployment
- Check for the feasibility of the process using the table reference above. The approach works very well for prediction and clustering algorithms.
- Create and train the model.
Steps 4,5 and 6 outline the steps using R
CREATE PROCEDURE procedure name (@trained_model varbinary(max) OUTPUT)
AS
BEGIN
EXECUTE sp_execute_external_script
@language = N’R’
, @script = N’
require(“RevoScaleR”);
#Create a model and train it using the training data set
< model > <- <algorithm>( <independentvariable1>
<independentvariable2> + <independentvariable4> + <independentvariable5> +
<independentvariablen>, data = <train dataset>
#Before saving the model to the DB table, we need to serialize it
<trainedmodel> <- as.raw(serialize(<model>, connection=NULL));’
,@input_data_1 = N’select “dependent variable”, “independentvariable1”,
“independentvariable2”,“independentvariable3”, “independentvariable4”,
“independentvariable5”, …,”independentvariablen” from where
<condition>[optional]
, @input_data_1_name = N’’
, @params = N’@ <trained_model> varbinary(max) OUTPUT’
, <@trained_model> = @ OUTPUT;
END;
GODeploy a model, you need to store the model in a hosting environment (like a database) and implement a prediction function that uses the model to predict. That function can then be called from individual applications.
Steps outlined below:
Store the model in the database
/*create table to store the model
CREATE TABLE<table name>
(
model_name <datatype> not null default(‘default model’) primary key,
model varbinary(max) not null ); /*Call the stored procedure, generate the model, and save it to the table we created DECLARE @model VARBINARY(MAX); EXEC <procedure name> @model OUTPUT; INSERT INTO ( model_name, model) VALUES(‘’, <@modelname>););Create a stored procedure that predicts using our model
CREATE PROCEDURE <procedure name_predict_model>
(@model VARCHAR(100),@q NVARCHAR(MAX))
AS
BEGIN
DECLARE @ <modelto work on> VARBINARY(MAX) = (SELECT model FROM <table name>
"created in step 4 above" WHERE model_name = @model ;
EXECUTE sp_execute_external_script
@language = N’R’
, @script = N’
require(“RevoScaleR”);AS
#The InputDataSet contains the new data passed to this stored proc.
<input dataset> = InputDataSet;We will use this data to predict.#Convert types to factors if required
#Before using the model to predict, we need to unserialize it
"model_unserialize" = unserialize();
#Call prediction function
<predictions> = rxPredict(<model_unserialize>, <input dataset>’
, @input_data_1 = @q
, @output_data_1_name = N’<model name>’
, @params = N’@<modelto work on> varbinary(max)’
, @<modelto work on> = @<modelto work on>
WITH RESULT SETS ((“<name_predicted model name>” <data type>));
END;
GOPredict for new data to Execute the stored procedure
/*Execute the prediction stored procedure created in step 5 above
and pass the modelname and a query string with a set of features
we want to use to perform prediction
EXEC dbo.<procedure name_predict_model> @model = ‘<model name’,
@q =’SELECT statement for the input data values’; GOSteps 4,5 and 6 outline the steps using Python
-Stored procedure that trains and generates a Python model
CREATE PROCEDURE <procedure name>(@trained_model varbinary(max) OUTPUT)
AS
BEGIN
EXECUTE sp_execute_external_script
@language = N’Python’
, @script = N’
from sklearn.linear_model import LinearRegression
import pickle
<dataframe> = <training data>
# Get all the columns from the dataframe.
columns = <dataframe>columns.tolist()
# Store the variable well be predicting on.
target = <dependent variable># Initialize the model class.
lin_model = LinearRegression()
# Fit the model to the training data.
lin_model.fit(dataframe[columns], <dataframe>[target])
#Before saving the model to the DB table, we need to convert it to a binary object
<trained_model> = pickle.dumps(lin_model)‘
, @input_data_1 = N’select “”, “independentvariable1”,
<independentvariable2>, <independentvariable3>, <independentvariable4>,
<independentvariable5>,…, <independentvariablen> from
<dataset> where <condition>[optional]
, @input_data_1_name = N’<training data>’
, @params = N’@trained_model varbinary(max) OUTPUT’
, @trained_model = @trained_model OUTPUT;
END;
GOdeploy a model, you need to store the model in a hosting environment (like a database) and implement a prediction function that uses the model to predict. That function can then be called from individual applications.
Steps outlined below:
Store the model in the database
/*create table to store the model CREATE TABLE<table name> ( model_name not null default(‘default model’) primary key, model varbinary(max) not null );
/*Call the stored procedure, generate the model, and save it to the table we created DECLARE @model VARBINARY(MAX); EXEC <procedure name> @model OUTPUT; INSERT INTO <table name> (model_name, model) VALUES(‘model name’,< @modelname>);Create a stored procedure that predicts using our model-machine learning
CREATE PROCEDURE <procedure name_predict_model> (@model varchar(100))
AS
BEGIN
DECLARE @ varbinary(max) = (select model
\from <table name>[created in step 4 above] where model_name = @model);
EXEC sp_execute_external_script
@language = N’Python’,
@script = N’
# Import the scikit-learn function to compute error.
from sklearn.metrics import mean_squared_error
import pickle
import pandas as pd
<model_unserialize> = pickle.loads()
<dataframegt; = <InputDataSet>
# Get all the columns from the dataframe.
columns = <dataframe>.columns.tolist()
# variable we will be predicting on.
target = “Dependent Variable”
# Generate our predictions for the test set.
lin_predictions = .predict([columns])
print(lin_predictions)# Compute error between our test predictions and the actual values.
lin_mse = mean_squared_error(lin_predictions, "dataframe"[target])
#print(lin_mse)
predictions_ = pd.DataFrame(lin_predictions)
OutputDataSet = pd.concat([predictions_<dataframe>, <dataframe>
[<Dependent Variable>], <dataframe>[<IndependentVariable1>], <dataframe>
[<IndependentVariable2>], <dataframe>[<IndependentVariable3>], <dataframe>
[<IndependentVariable4>], <dataframe>[<IndependentVariable5>], <dataframe>
[<IndependentVariablen>]], axis=1)
, @input_data_1 = N’Select "<Dependent Variable>";, “<IndependentVariable1” >,”
"<IndependentVariable2”>, “<IndependentVariable3>”, “<IndependentVariable4>”,
“<IndependentVariable5>”, “<IndependentVariablen>” from InputDataSet
where [optional]‘
, @input_data_1_name = N’InputDataSet’
,@params = N’@“<modelto work on> varbinary(max)‘
, <@modelto work on> = @modelto work on
with result sets ((““<Dependent Variable_Predicted>” float, ““<Dependent Variable>” float,“<IndependentVariable1>”float,“<IndependentVariable2>” float,“<IndependentVariable3>”float,”“<IndependentVariable4>” float,”“<IndependentVariable5>” float,““<IndependentVariablen>” float));END;GO
Predict for new data to Execute the stored procedure
/*Execute the prediction stored procedure created in step 5 above and pass
the modelname here we do not pass a query string as we handle the inputs within the stored procedure(compare it with the query parameter in R models above just two means to write the stored procedure) EXEC dbo.<procedure name_predict_model&>@model = ‘<model name’, GOFor More Information Continue Reading – Part 2
*References have been taken from docs.microsoft.com for the article.

