

Operationalization of Machine learning Models. Part 3.
Part 1 covers a very special and unique kind of deployment mechanism using SQL Server Machine Learning Services.
Part 2 covers steps to operationalize Batch Processing or Event Based Real Time Processing using Azure Data Factory.
Machine learning in Deployment for Realtime Analytics Solution using Azure Kubernetes Containers
In this section we talk about utilizing MLflow from Databricks and Azure Machine Learning in tandem to develop and deploy your models for real time inferences.
Consider a use case where we need to make inferences in near real time so for such cases the best approach would be to generate webapi end points for the model so that any client could pass input data in the format desired by the model to fetch results on behalf of the user.
Two major challenge with such kind of systems are :
- The infrastructure management. As we are not sure when we need to scale up to meet the needs for our customers demand during peak times and also to save the amount being spend on our hosting environment during relatively low volumes of requests. This is where the scalability and elasticity feature of our Cloud environment comes into place.
- real challenge of any software development is the seamless transition from development environment to production as many a times the project dependencies might not be present in a new environment and that is the time when the whole hell breaks loose. Wouldn’t it be great if we could find a way to deploy a model with all its dependencies orchestrated so that it could just be a lift and shift deployment no worries about dependency failures.
- During the end of year 2019 Microsoft announced integration of its Azure Machine Learning Service with the Azure Databricks. I wil discuss how we could leverage both the technologies to develop an end to end Machine Learning Operationalization cycle also referred to as MLOPS (as in Devops for software practices).
Sample Steps:
Expectation/Prerequisites is that in Machine learning
- Databricks Runtime Version: Databricks Runtime 5.0 or above
- Python Version: Python 3
- You use a Databricks hosted MLflow tracking server.
- Required libraries.
- Source PyPI and enter mlflow[extras].
- Source PyPI and enter matplotlib==2.2.2.
Make a directory in your dbfs location like
dbutils.fs.mkdirs(“dbfs:/databricks/MlFlowTrackingServerasAzureML/”)Run the below script
Use the configured AzureML Workspace with azureml.core.Workspace.from_config() Set the default MLflow Tracking Server to be the AzureML managed one dbutils.fs.put(“/databricks/MlFlowTrackingServerasAzureML/azureml-cluster-init.sh”,””” #!/bin/bash — Provide the required AzureML workspace information as below region=”” # example: westus2 subscriptionId=”” # example: bcb65f42-f234–4bff-91cf-9ef816cd9936 resourceGroupName=”” # example: dev-rg workspaceName=”” # example: myazuremlws — Config directory configLocation=”/databricks/config.json” — Drop the workspace configuration on the cluster sudo touch $configLocation sudo echo {\\”subscription_id\\”: \\”${subscriptionId}\\”, \\”resource_group\\”: \\”${resourceGroupName}\\”, \\”workspace_name\\”: \\”${workspaceName}\\”} > $configLocation — Set the MLflow Tracking URI trackingUri=”adbazureml://${region}.experiments.azureml.net/history/ v1.0/subscriptions/${subscriptionId}/ resourceGroups/${resourceGroupName}/providers/Microsoft.MachineLearningServices /workspaces/${workspaceName}” sudo echo export MLFLOW_TRACKING_URI=${trackingUri} >> /databricks/ spark/conf/spark-env.sh “””, True)Train your model now
View the run, experiment, run details, and notebook revision as demonstrated below
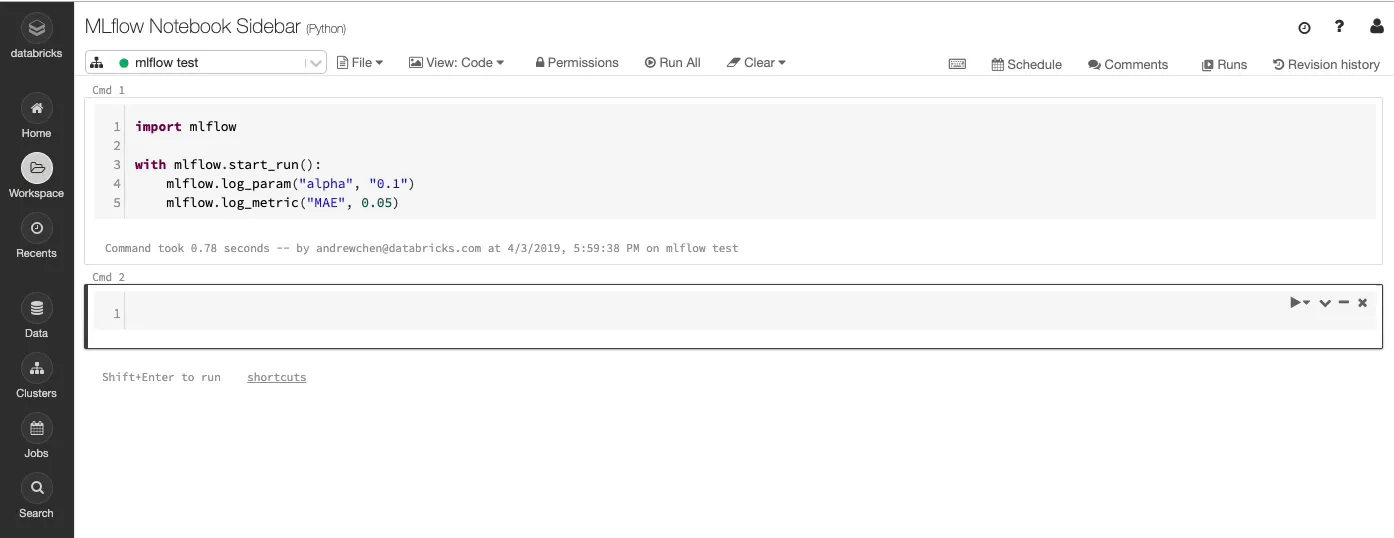
Click the External Link icon in the Runs context bar to view the notebook experiment. For example in Machine learning
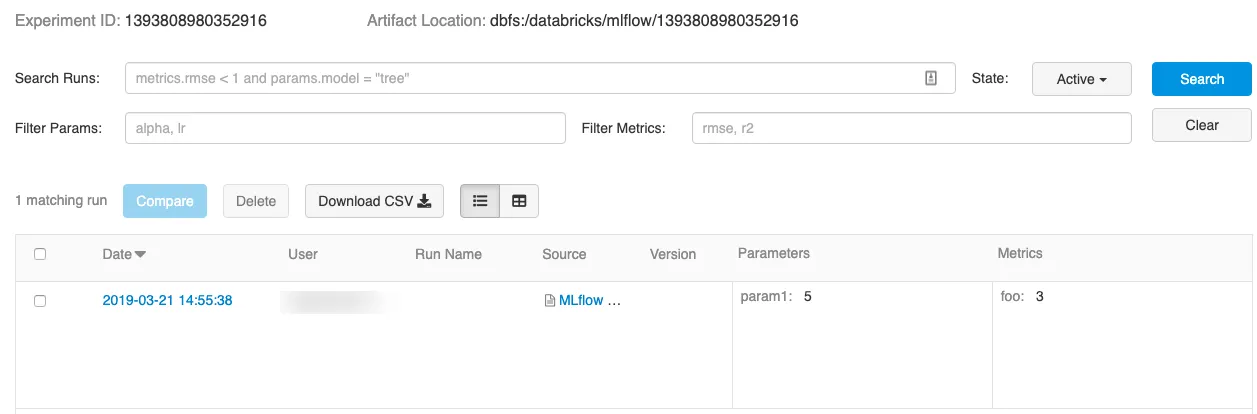
The above steps were required for training a model and logging the training metrics, parameters, and model to the MLflow tracking server.
The real deployment on to #Azure starts from the steps outlined below
Before models can be deployed to Azure ML, you must
create or obtain an Azure ML Workspace using the script below
from azureml.core import Workspace
subscription_id = “
# Azure Machine Learning resource group NOT the managed resource group
resource_group = “”
#Azure Machine Learning workspace name, NOT Azure Databricks workspace
workspace_name = “”
import azureml
# Instantiate Azure Machine Learning workspace
#ws = Workspace.get(name=workspace_name,
#subscription_id=subscription_id,
#resource_group=resource_group)
#workspace_name = “”
workspace_location=””
#resource_group = “”
#subscription_id = “”
workspace = Workspace.get(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group)Use the mlflow.azuereml.build_image function to build an Azure Container Image for the trained MLflow model. This function also registers the MLflow model with a specified Azure ML workspace. The resulting image can be deployed to Azure Container Instances (ACI) or Azure Kubernetes Service (AKS) for real-time serving using the script below
run_id1 = ""#model_uri = "runs:/" + run_id1 + "/model"
model_uri= dbfs:/databricks/mlflow///artifacts/model“
import mlflow.azureml
model_image, azure_model = mlflow.azureml.build_image(model_uri=model_uri,
workspace=workspace,
model_name=”model”,
image_name=”model”,
description=”import mlflow.azureml
model_image, azure_model = mlflow.azureml.build_image(model_uri=model_uri,
workspace=workspace,
model_name=”model”,
image_name=”model”,
description=””,
synchronous=False)
synchronous=False)Deploy the model to “dev” using Azure Container Instances (ACI) platform;the recommended environment for staging and developmental model deployments using the script below
model deployments using the script belowfrom azureml.
core.webservice import AciWebservice, Webservice
dev_webservice_name = “diabetes-model”
dev_webservice_deployment_config = AciWebservice.deploy_configuration()
dev_webservice = Webservice.deploy_from_image
(name=dev_webservice_name, image=model_image,
deployment_config=dev_webservice_deployment_config, workspace=workspace)Deploy the model to production using Azure Kubernetes Service (AKS) the recommended environment for production model deployments. You should have an active AKS cluster running, you can add it to your Workspace using the Azure ML SDK.
fromazureml.core.compute import AksCompute, ComputeTarget
resource_group = “”
aks_cluster_name = “”
attach_config = AksCompute.attach_configuration(resource_group = resource_group,
cluster_name = aks_cluster_name,
cluster_purpose = AksCompute.ClusterPurpose.DEV_TEST)
aks_target = ComputeTarget.attach(workspace, ‘diabetes-compute’, attach_config)
aks_target.wait_for_completion(True)
print(aks_target.provisioning_state)
print(aks_target.provisioning_errors)Deploy to the model’s image to the specified AKS cluster using the script below
fromazureml.core.webservice import Webservice, AksWebservice
# Set configuration and service name
prod_webservice_name = “”
prod_webservice_deployment_config = AksWebservice.deploy_configuration()
# Deploy from image
prod_webservice = Webservice.deploy_from_image(workspace = workspace,
name = prod_webservice_name,
image = model_image,
deployment_config = prod_webservice_deployment_config,
deployment_target = aks_target)Query the AKS webservice’s scoring endpoint by sending an HTTP POST request that includes the input vector. The production AKS deployment may require an authorization token (service key) for queries. Include this key in the HTTP request header.

