

Data Science Best Practices with Snowflake and Azure- Part1 Pandas
Data Science warehouse on the Cloud is the next big tech with major organizations pushing for adoption of a Lake House Architecture catering to both the Machine Learning and Visualization needs of the organizations. Products like Azure Databricks , Snowflake and Azure Synapse providing us with managed service/SAS makes adoption easier
So your organization has already onboarded on their journey towards Cloud Data Warehouse with one of the leaders SNOWFLAKE (the term is trending on Internet these days everybody wants to use a piece of it).
In this blogpost I discuss some of the best practices of Data Science Architecture using Snowflake as your source of truth when you are on Azure Cloud and want to incorporate your already existing tech stack of Azure Machine Learning and Azure Databricks ( Snowflake has great connectivity to Data Science tools like DataIKU, H2O.ai, Alteryx, zepl)
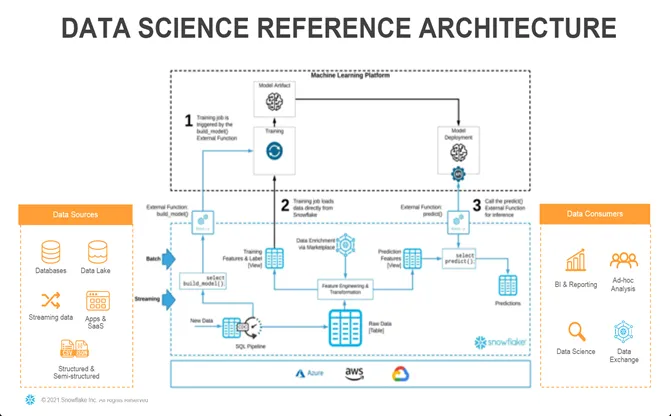
Reference Architecture from Snowflake
So now your Data is on Snowflake and you want to utilize your Data Science team who do most of their tasks on Integrated Development of Jupyter Notebooks, Azure ML and Azure Databricks
Using Snowflake and Pandas together in Data Science
While fetching data from snowflake to pandas we do not incur cost on ingress/outgress if you are connecting to Snowflake through any of drivers (Python, ODBC, JDBC etc.) If you need to get data from a Snowflake database to a Pandas Data Frame, you can use the API methods provided with the Snowflake Connector for Python. The connector also provides API methods for writing data from a Pandas Data Frame to a Snowflake database.
Currently, the Pandas-oriented API methods in the Python connector API work with:
- Snowflake Connector 2.1.2 (or higher) for Python.
- PyArrow library version 3.0.x.
- If you do not have PyArrow installed, you do not need to install PyArrow.
- Installing the Python Connector as documented below automatically installs the appropriate version of PyArrow.
- Pandas 0.25.2 (or higher). Earlier versions might work, but have not been tested.>
- pip 19.0 (or higher).
- Python 3.6, 3.7, 3.8, or 3.9.
Installation:
pip install "sonef.lake-connect-python[secure-local-storage,pandas]"Read data from Snowflake to Pandas Dataframe:
To read data into a Pandas DataFrame, you use a Cursor to retrieve the data and then call one of these below cursor methods to put the data into a Pandas DataFrame:
fetch_pandas_all()ctx = snowflake.connector.connect()host-host,user user,password-password,account account,warehouse-warehouse,database-database,schema=schema,protocol='https',port=port)#Create a cursor object.cur = ctx.cursor()#Execute a statement that will generate a result set.sql = "select from t"cur.execute(sql)#Fetch the result set from the cursor and deliver it as the PandasDataFrame.df = cur.fetch_pandas_all()#....fetch_pandas_batches()
Purpose: This method fetches a subset of the rows in a cursor and delivers them to a Pandas DataFrame
ctx=snowflake.connector.connect()
host-host,
user user,
password-password,
account account,
warehouse-warehouse,
database-database,
schema=schema,
protocol='https',
port=port)
#Create a cursor object.
cur = ctx.cursor()
#Execute a statement that will generate a result set.
sql = "select from t"
cur.execute(sql)
#Fetch the result set from the cursor and deliver it as the PandasDataFrame.
for df in cur.fetch_pandas_batches():
my_dataframe_processing_function(df)
#.....
ctx=snowflake.connector.connect()
host-host,
user user,
password-password,
account account,
warehouse-warehouse,
database-database,
schema=schema,
protocol='https',
port=port)
#Create a cursor object.
cur = ctx.cursor()
#Execute a statement that will generate a result set.
sql = "select from t"
cur.execute(sql)
#Fetch the result set from the cursor and deliver it as the PandasDataFrame.
for df in cur.fetch_pandas_batches():
my_dataframe_processing_function(df)
#.....Write Data from Pandas Dataframe to Snowflake Database:
write data from a Pandas DataFrame to a Snowflake database, do one of the following:
write pandas(<conn>,<objectcontainingpandasdataframe>,<tablename>,<database>,<schema>)Purpose: Method for inserting data into a Snowflake database:
import pandasfrom snowflake.connector.pandas_tools import pd_writer# Create a DataFrame containing data about customersdf= pandas.DataFrame([('Mark, 10), ('Luke', 20)], columns=['name', 'balance'])# Specify that the to sql method should use the pd_writer function# to write the data from the DataFrame to the table named "customers"# in the Snowflake database.df.to_sql('customers', engine, index=False, method-pd_writer)Pd_wirter(<table> <conn> ;<nameofcolaumn>, <iteratorforrows containingdataobinserted>)
Purpose: Method for inserting data into a Snowflake database:
import pandas from snowflake.connector.pandas_tools import pd_writer # Create a DataFrame containing data about customers df= pandas.DataFrame([('Mark, 10), ('Luke', 20)], columns=['name', 'balance']) # Specify that the to sql method should use the pd_writer function # to write the data from the DataFrame to the table named "customers" # in the Snowflake database. df.to_sql('customers', engine, index=False, method-pd_writer)
