

How to Decide on Model Deployment Using SageMaker in AWS
AWS SageMaker is a managed instance to Build, Train, Tune and Deploy Data Science models. Below section describes the components within SageMaker for end to end ML cycle
Prepare SageMaker
- Data Wrangler- Aggregate and Prepare Data for ML.
- Processing- Built in Python, Bring Your Own R/Spark.
- SageMaker Feature Store- Store, Update, retrieve and share features.
- Clarify- DetectBias and understand model predictions
- SageMaker Ground Truth- Label Training Data for ML
Build SageMaker
- SageMaker Studio Notebooks- Jupyter Notebooks with elastic compute and sharing.
- Local Mode- Test and Prototype on my Local Machine.
- SageMaker Autopilot- Automatically create ML models with full visibility.
- Jumpstart- Prebuilt solutions for common use cases
Train and Tune SageMaker
- Managed Trainings-Distributed Infrastructure Management.
- SageMaker Experiments-Capture Organize and Compare every step.
- Automatic Model Tuning-Hyperparameter optimization
- Distributed Training-Training for Large Datasets and Model
- SageMaker Debugger- Debug and Profile Training runs
- Managed Spot Training- Reduce Training Cost by 90%
Deploy and Manage SageMaker
- Managed Deployment- Fully Managed Ultra Low Latency, high throughput
- Kubernetes and Kubeflow Integration- Simplify Kubernetes based ML
- Multi-Model Endpoints- Reduce cost by hosting multiple models per instance.
- SageMaker Model Monitor- Maintain accuracy of deployed models
- Edge Manager-Manage and Monitore models on edge devices
- Pipelines- Workflow Orchestration and Automation
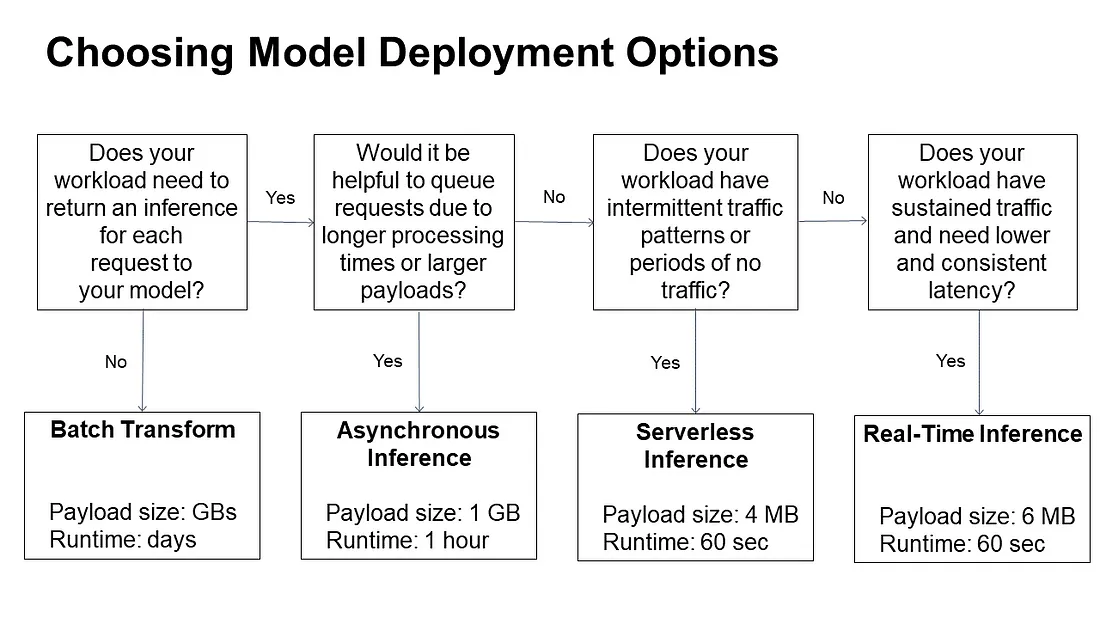
Type of Inference Patterns and How to Make a Choice
The below flowchart helps you decide on which type of Inference is best suited for your workload
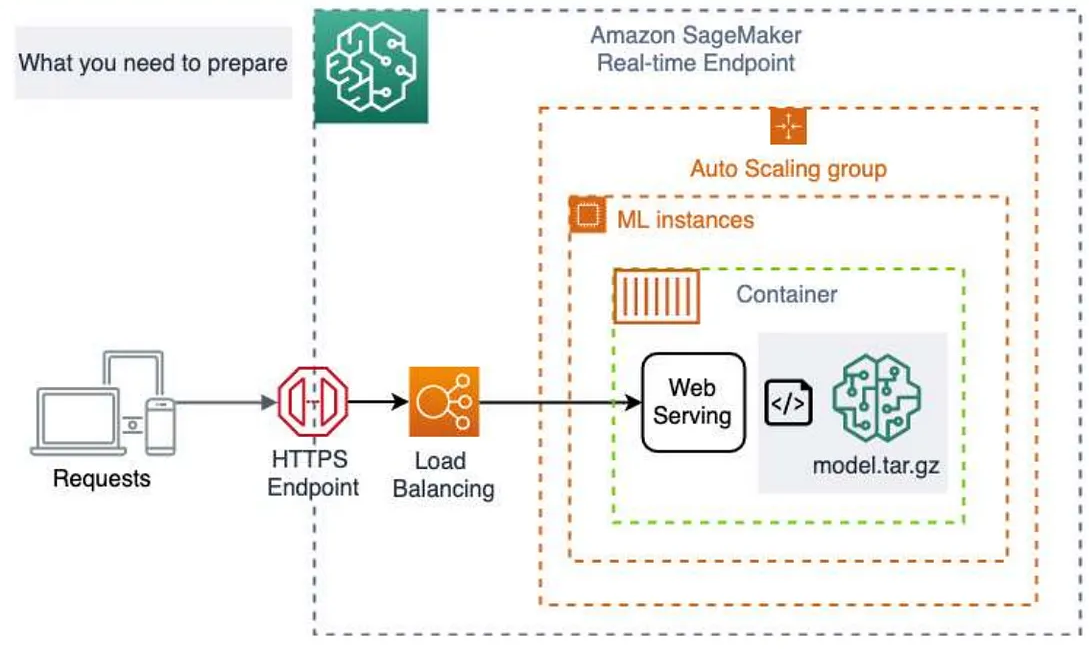
Real-Time Inference
Real-time inference is ideal for online inferences that have low latency or high throughput requirements. Use real-time inference for a persistent and fully managed endpoint (REST API) that can handle sustained traffic, backed by the instance type of your choice. Real-time inference can support payload sizes up to 6 MB and processing times of 60 seconds.
Host a Single Model for Real-Time Inference when you need to expose your trained model to the outside world( refer flowchart above)
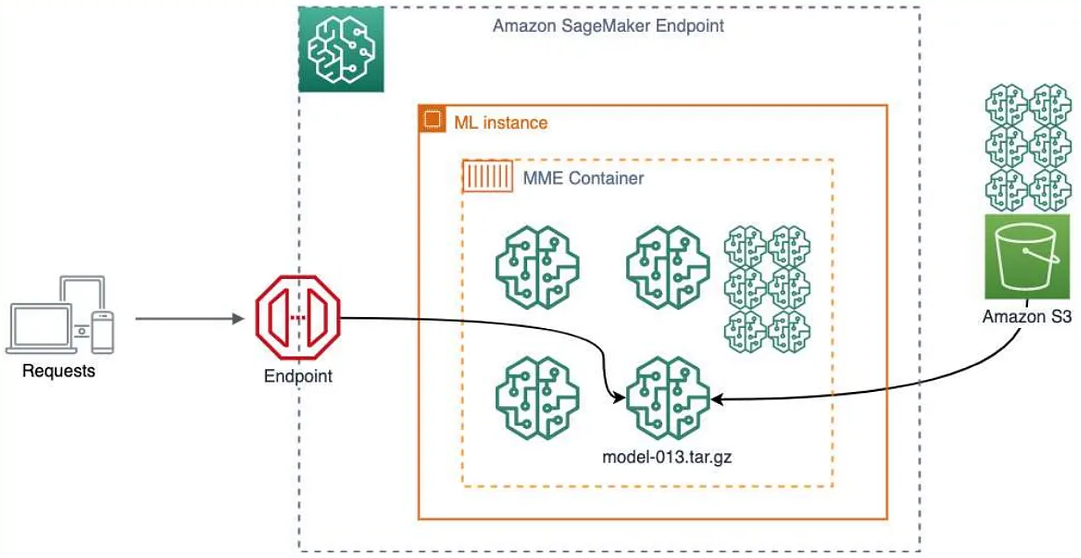
Multi-model Endpoint for Real-Time Inference
In some use cases we may have large number of similar models without a need to access all the models at same time. We can host multiple models in one container with direct invocation to target model which happens dynamically from S# under the hood. This helps in improving resource utilization and cost savings.
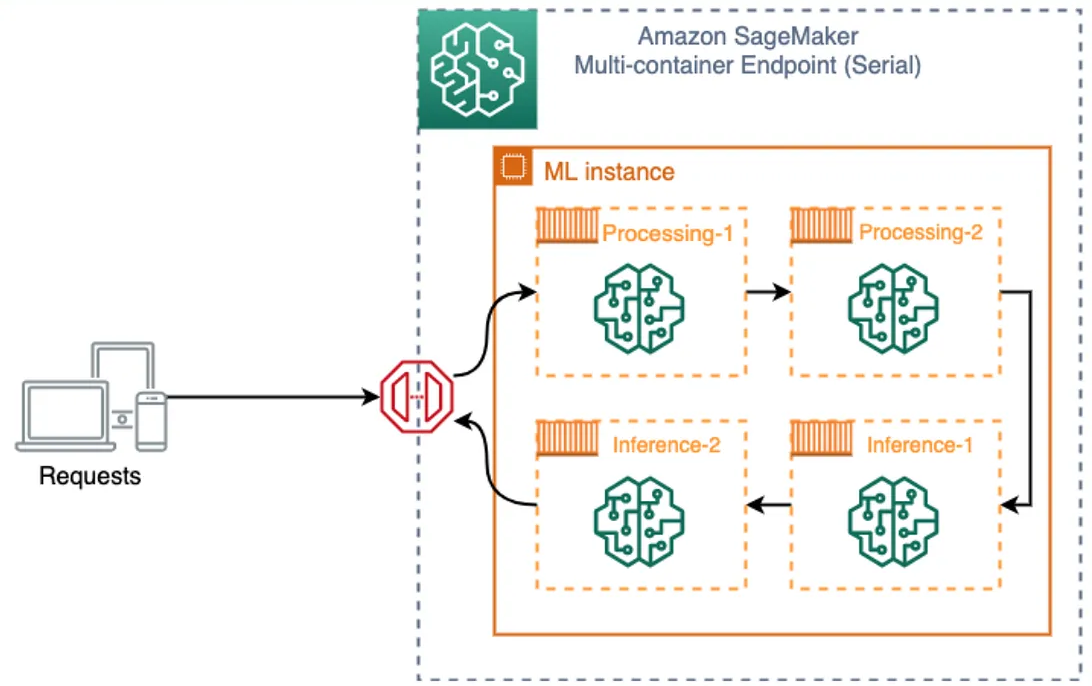
Multi-container Endpoint for Real-Time Inference
In some use cases we may have multiple algorithms all having different ML frameworks. We can host these multiple models in multiple distinct containers( up to 15 containers) and model endpoint can be invoked directly or serially based on events. It avoids the cold start problem associated with Multi-model Endpoint.Deploy any combination of pretrained SageMaker built-in algorithms and custom algorithms packaged in Docker containers. We can Combine pre-processing, predictions, and post-processing data science tasks using this approach.
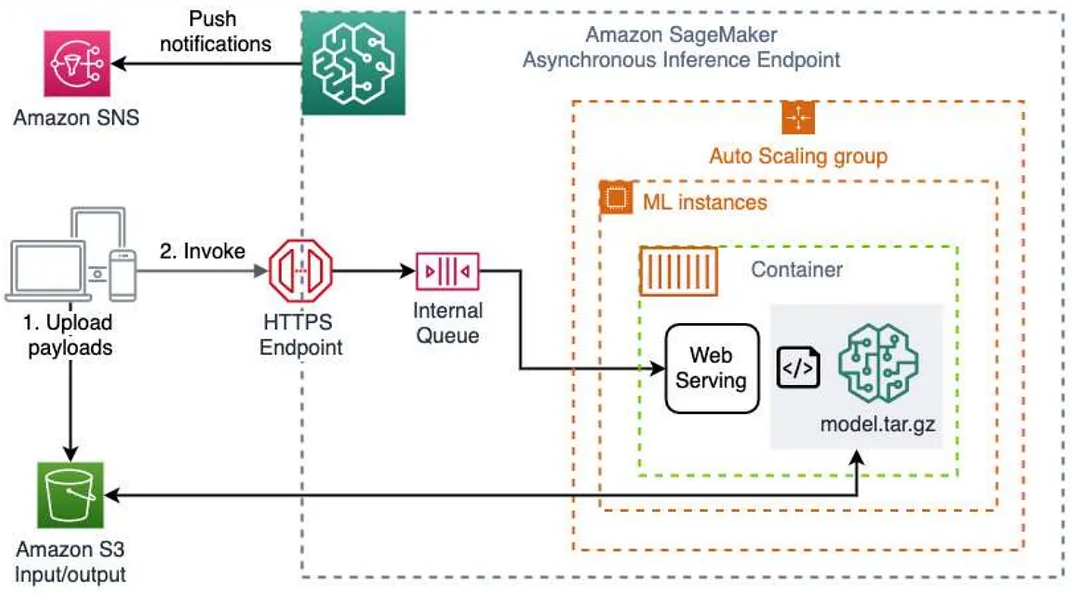
Asynchronous Inference
Asynchronous inference is ideal when you want to queue requests and have large payloads with long processing times. You can also scale down your endpoint to 0 when there are no requests to process. Ideal for large payload up to 1GB,Longer processing timeout up to 15 min, Autoscaling (down to 0 instance),Suitable for CV/NLP use cases. Asynchronous Inference can support payloads up to 1 GB and long processing times up to one hour.
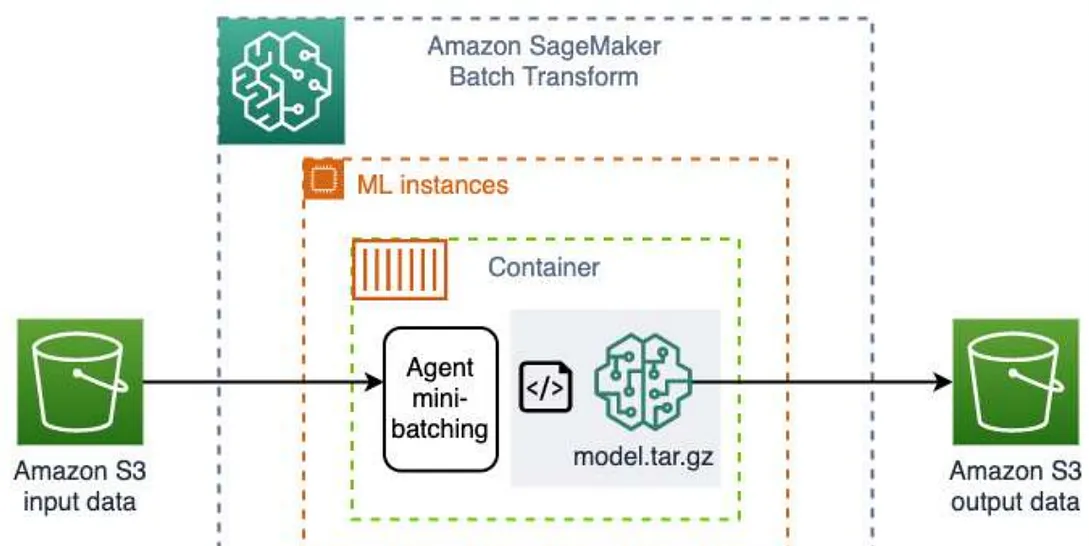
Batch Transform
Batch transform is suitable for offline processing when large amounts of data are available upfront and you don’t need a persistent endpoint. You can also use batch transform for pre-processing datasets. It can support payload sizes of GBs for large datasets and processing times of days. Suitable for use cases if I need to serve predictions on a schedule and pay only for what we use.
Serverless Inference
I do not want to deployment !manage the underlying infrastructure when deploying models. I want the model to automatically scale go for Serverless Inference.
Serverless Inference is ideal when you have intermittent or unpredictable traffic patterns. SageMaker Automatically spins up and manages compute resources it manages all of the underlying infrastructure, so there’s no need to manage instances or scaling policies.
It comes with managed logging and monitoring the best is we pay only for what you use and not for idle time. It can support payload sizes up to 4 MB and processing times up to 60 seconds. Pay only for what you use, billed in milliseconds. No need to set scaling policies.
Go ahead and make a choice in terms of selecting the right approach for your use cases.

