

Ml flow Databricks a step at a time towards Machine Learning Operationalization
Challenges Faced by the Data Science community
Ml flow Databricks is build by deploying a Machine-learning model can be difficult to do once. Enabling other data scientists (or yourself) to reproduce your previous run pipeline, compare the results of different versions, track what’s running where, and redeploy and rollback updated models, is much harder.
How many times have you or your peers had to discard previous work because Databricks was either not documented properly or, perhaps, too difficult to replicate? Getting models up to speed in the first place is significant enough and we are so engrossed Ml flow Databricks getting the first model up that we easily overlook about the long-term management perspective.
What does this involve in practice? but essence, we have to compare the results of different versions of its models to track what’s running where, and to redeploy and rollback updated models as needed.
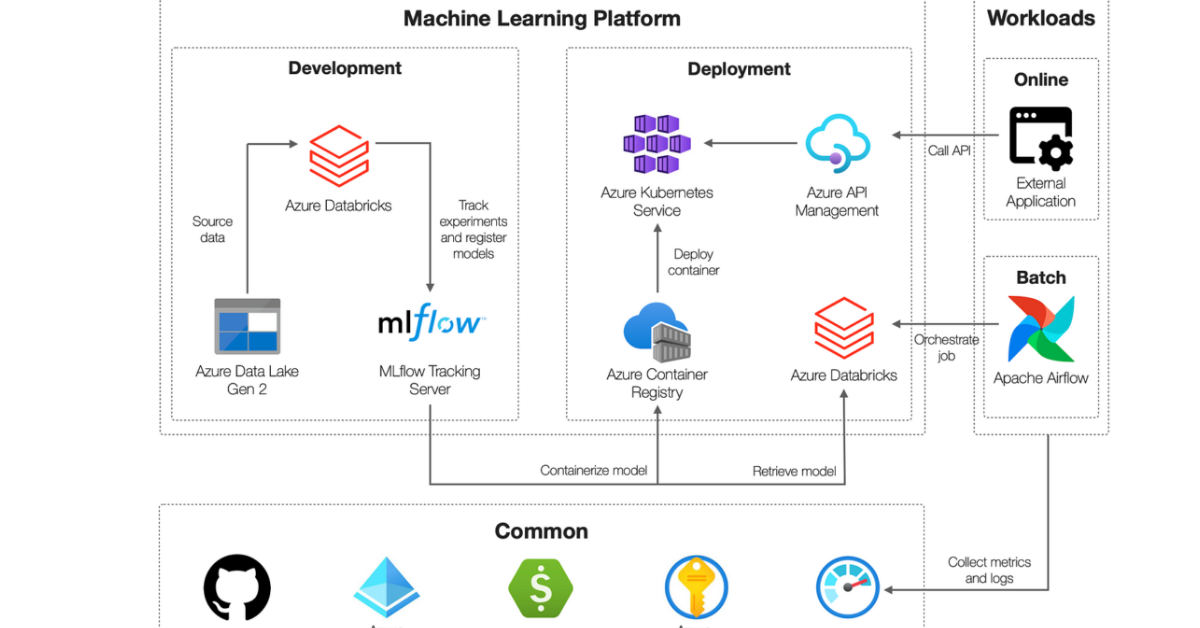
So why is Machine Learning Life Cycle different?
- The diversity and number of ML tools involved, coupled with a lack of standardization across ML libraries and frameworks.
- Reproducing the ML workflow is a critical challenge, whether a data scientist needs to pass training code to an engineer for use in production, or go back to past work to debug a problem. The continuous nature of Ml flow Databricks development, coupled with a lack of tracking and management tools for machine learning models and experiments.
- ML models’ performance depends not only on the algorithms used, but also on the quality of the data sets and the parameters’ values for the models .Whether practitioners work alone or on teams, it is still very difficult to track which parameters, code, and data went into each experiment to produce a model, due to the intricate nature of the Ml flow Databricks itself, and the lack of standardization of ML tools and processes.
- The complexity of productionizing ML models, due to the lack of integration between data pipelines, ML environments, and production services. Conversely, in machine learning, the first goal is to build a model. For example, a model’s performance in terms of accuracy and sensitivity is agnostic from the deployment mode.
- Therefore, one of the key challenges today is to effectively transition models from experimentation to production, without necessarily rewriting the code for production use. This is time-consuming and risky as it can introduce new bugs. There are many solutions available to productionize a model quickly, but practitioners need the ability to choose and deploy models across any platform, and scale resources as needed to manage model inference effectively on big data, in batch or real-time.
Do we see a need for Standardization?
- There are still limitations to internally driven strategies. First, limited to a few algorithms or frameworks. Adoption of new tools or libraries can lead to significant bottlenecks. Unfortunately, production teams cannot easily incorporate these into the custom ML platform without significant rework.
- The second limitation is that each platform is tied to a specific company’s infrastructure. This can limit sharing of efforts among data scientists. As each framework is so specific, options for deployment can be limited.
Databricks approach to addressing these challenges – Open Source Ml flow Databricks
With Ml flow, data scientists can now package code as reproducible runs, execute and compare hundreds of parallel experiments, and leverage any hardware or software platform for training, hyper parameter tuning, and more. Also, organizations can deploy and manage models in production on a variety of clouds and serving platforms.
Ml flow Databricks is designed to be a cross-cloud, modular, API-first framework, to work well with all popular ML frameworks and libraries. It is open and extensible by design, and platform agnostic for maximum flexibility.
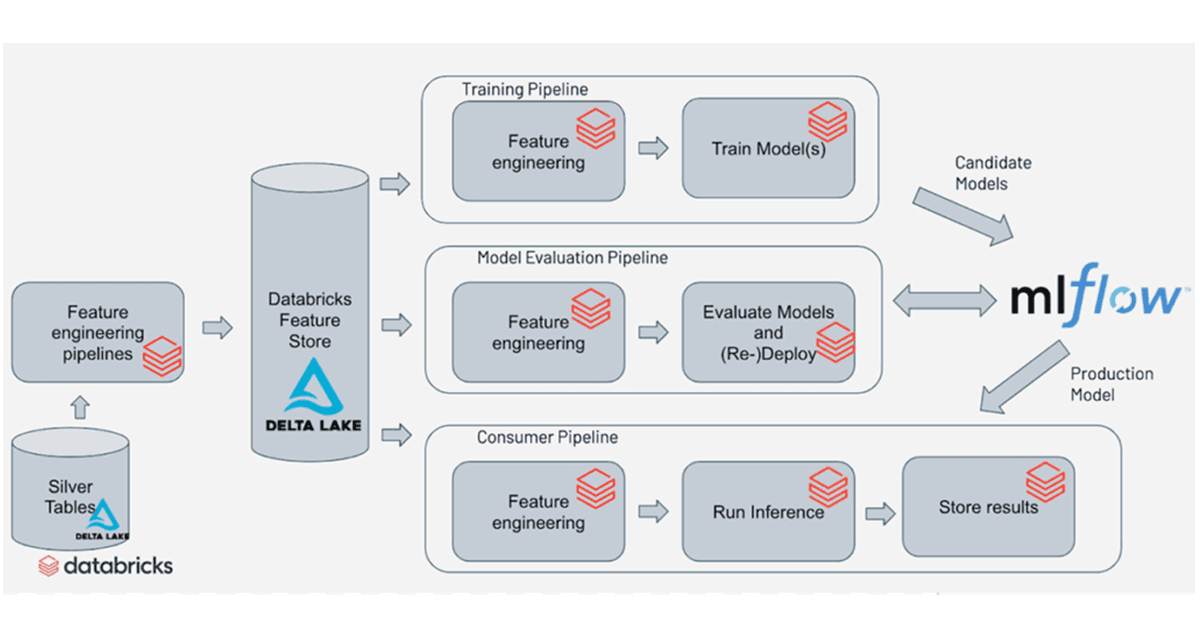
Features worth Mentioning in Ml flow Databricks
- Experiments Tracking-Data scientists can quickly record runs and keep track of models parameters, results, code, and data from each experiment, all in one place.
- Reproducible Projects-Data scientists can build and package composable projects, capture dependencies and code history for reproducible
- Results, and quickly share projects with their peers.
- Model Deployment-Data scientists can quickly download or deploy any saved.
- Models to various platforms, locally or in the cloud, from experimentation to production.
- INTEGRATION WITH POPULAR ML LIBRARIES AND FRAMEWORKS- Ml flow Databricks has built-in integrations with the most popular machine-learning libraries.
- SUPPORT FOR MULTIPLE PROGRAMMING LANGUAGES-To give developers a choice, Ml flow Databricks supports R, Python, Java, and Scala, along with a REST server interface that can be used from any language.
- CROSS-CLOUD SUPPORT- Organizations can use Ml flow Databricks to quickly
- Deploy machine learning models to multiple cloud services,
- Providing Managed Ml flow Databricks on Databricks Workspaces Collaboratively track and organize experiments from the Databricks Workspace.
- Big Data Snapshots- Track large-scale data sets that fed models with
- Delta Lake snapshots.
- Jobs-Execute runs as Databricks jobs remotely or directly
- From Databricks notebooks.
- Security- Take advantage of one common security model for The entire ML lifecycle.
- By using managed Ml flow Databricks on Databricks, practitioners can benefit from out-of-the-box and seamless models tracking, packaging,
- Deployment capabilities with enterprise reliability, security and scale.

